Hi, I am creating training datasets with use of JDBC connector to postgresql database with use of on-demand feature groups. When using Jupyter notebook I configure the Spark environment and attach a JAR postgresql JDBC connector file from the /Resources directory:

In case of Jupyter everything goes well and the datasets are created. However if I start to create the same training dataset manually in Feature Store UI (by just picking features and adding them to the basket) a job is being created. The job however fails, I assume that is due to lack of JDBC driver.
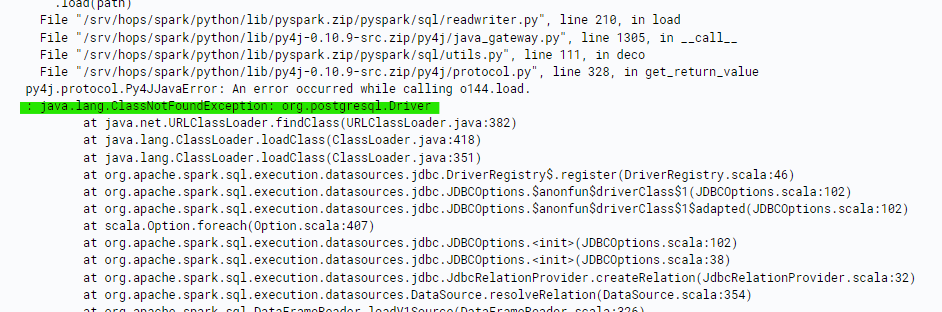
Should I modify the Hopsworks environment somehow and attach the driver somewhere to make it work? Ideally would be to execute the code from PyCharm on my local machine, but I guess that is the same environment which lacks postgresql driver.
Kind regards,
Krzysztof