I have a notebook written in python in which I create a feature group and insert a pandas dataframe into the feature group. I run this notebook from my local environment by connecting to hopsworks using hsfs. I noticed that when running this notebook, Hopsworks would create a pyspark job which would ingest the data into the feature store. I want to schedule a job so that the feature group version is updated each time the data is ingested. Please help on how I could do this.
A way to achieve incrementing the FG version every time data is ingested would be in the client code to create the FG by using the same name and then calling the FG save() function. This way, every time the job runs, it will create a new version and ingest the data.
However, feature group versions are mostly meant to be used for managing feature group schema updates. The recommended way for data versioning is to enable time travel for the feature group when it is created and then use the insert() function
https://docs.hopsworks.ai/latest/generated/api/feature_group_api/#create_feature_group
An example using PySpark is the following Time-Travel with PySpark
I tried the insert() function. Although the statement worked, I didn’t see any version update in the features. The version against the features still shows 1.
Also please let me know on how I can get my ipython notebook(written in python) currently in my local environment that performs the feature engineering and insertion into feature group to be scheduled to run as a job in Hopsworks. Because, when I run the notebook from my local environment, I see that in Hopsworks the insertion job takes place as a pyspark job and the app file is a py file called ‘hops-utils…’.py.
The insert() does not increment the feature group version automatically. To achieve that you can do
# assuming a Pandas df "pdf"
my_fg = fs.create_feature_group("my_fg") # version 1 is created here
my_fg.save(pdf)
my_fg = fs.create_feature_group("my_fg") # version 2 is created here
my_fg.save(pdf)
The insert() will ingest data into the save version but you can use time travel as described above to achieve data versioning.
Keep in mind that in this scenario in which the local client inserts a Pandas df into the feature group, it is up to the client to provide the new df to be ingested. In this case the notebook in the local client would need to be scheduled, not the ingestion job in Hopsworks. Otherwise the ingestion job in Hopsworks will keep inserting the same Pandas df every time it runs. The feature store provides storage connectors Overview - Hopsworks Documentation to ingest data into a feature group from external data sources.
Regarding scheduling, Hopsworks provides Airflow for scheduling jobs Apache Airflow — Documentation 2.2 documentation
Hopsworks comes with a UI that enables you to create workflows such one to run a single job periodically but also more complex workflows with multiple jobs.
So if I upload the notebook onto Hopsworks and create a job to run it, what job parameters should I provide, like the job type(the notebook contains python code), default argument etc, and will the app file to be provided be the ipython notebook?
I tried running a job with the app file as the ipython notebook and the job type as python. I am not sure on what to provide under default argument here. So I just provided ‘1’ randomly. I am getting the following error:
io.hops.hopsworks.exceptions.ServiceException
I attach an example notebook that create a pandas df and ingests it into the feature store. Let me know if it works or if the ServiceException error is thown. In this case, if you have access to command line, you can look into the /srv/hops/domains/domain1/logs/server.log log file for more details.
To run it as a job in Hopsworks, you need to navigate to the Jobs service in Hopsworks, then New Job, give it a name (for example my_pandas_job), select the Python job type and leave everything else as per the default values. The default arguments is optional, you do not need to set it. Then from the Airflow service on the left menu in the project you can create a simple workflow by using the my_pandas_job job that you created.
pandas_job.ipynb (3.1 KB)
Using the notebook provided, initially I got the following error:
HTTP code: 400, HTTP reason: Bad Request, error code: 270040, error msg: Illegal feature name, user msg: , the provided feature name Name is invalid. Feature names can only contain lower case characters, numbers and underscores and cannot be longer than 63 characters or empty.
So after making the feature names lowercase and running, a message pops up ‘An error occurred while trying to start this job’ and I see the previous error in the error log:
io.hops.hopsworks.exceptions.ServiceException
P.S: The default argument should mandatorily be provided before running the job and hence I randomly gave 1.
Hi.
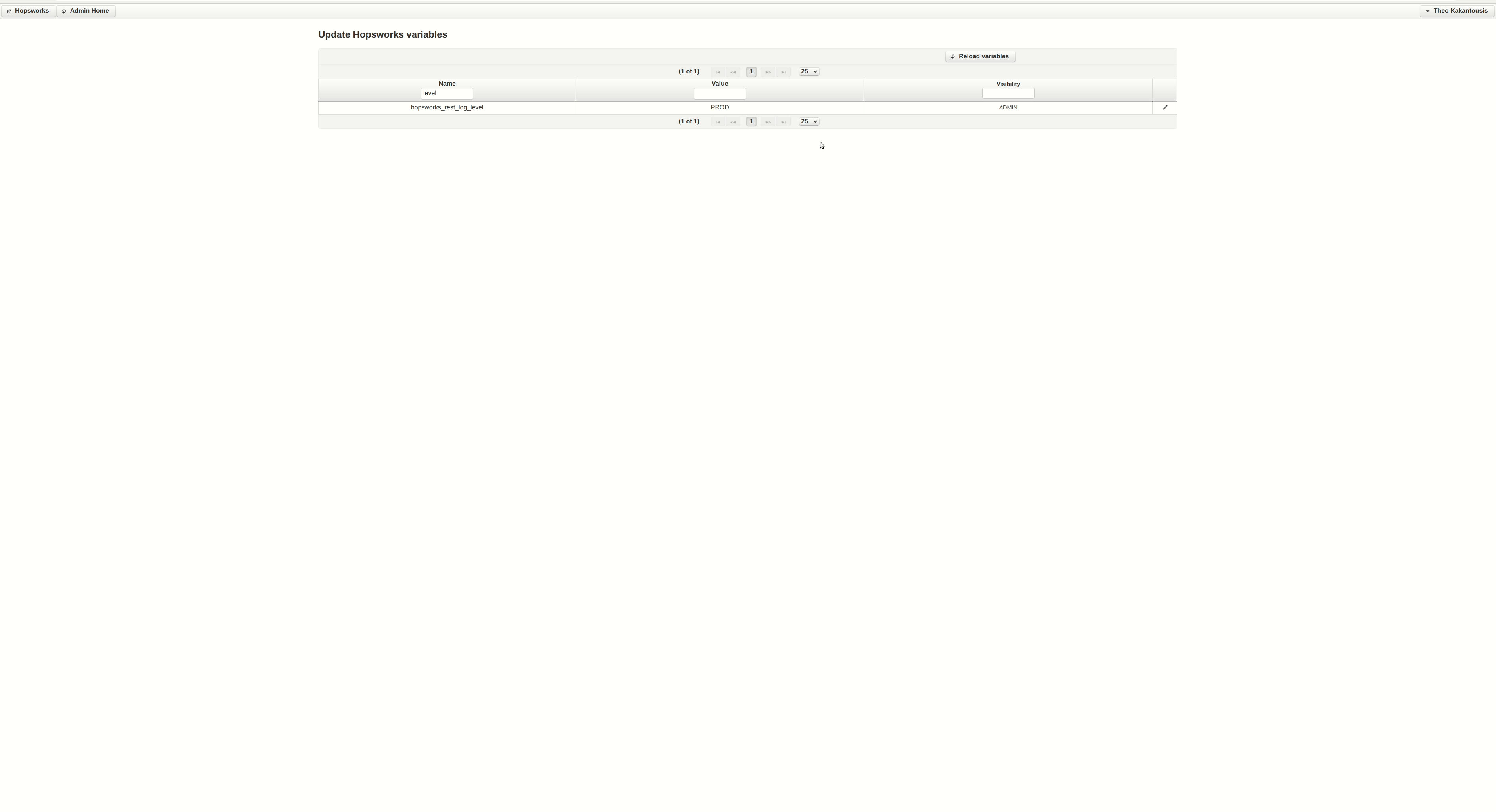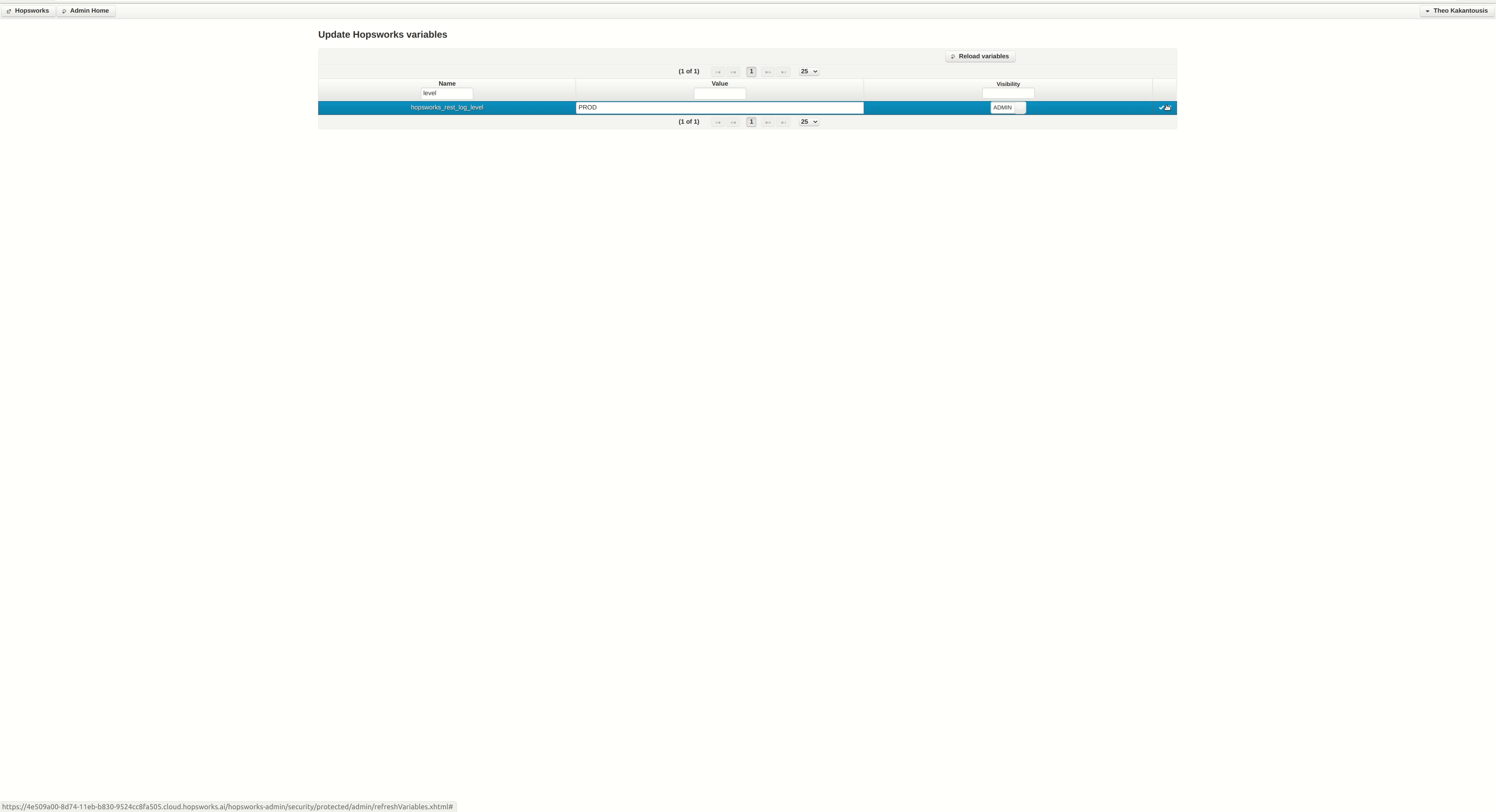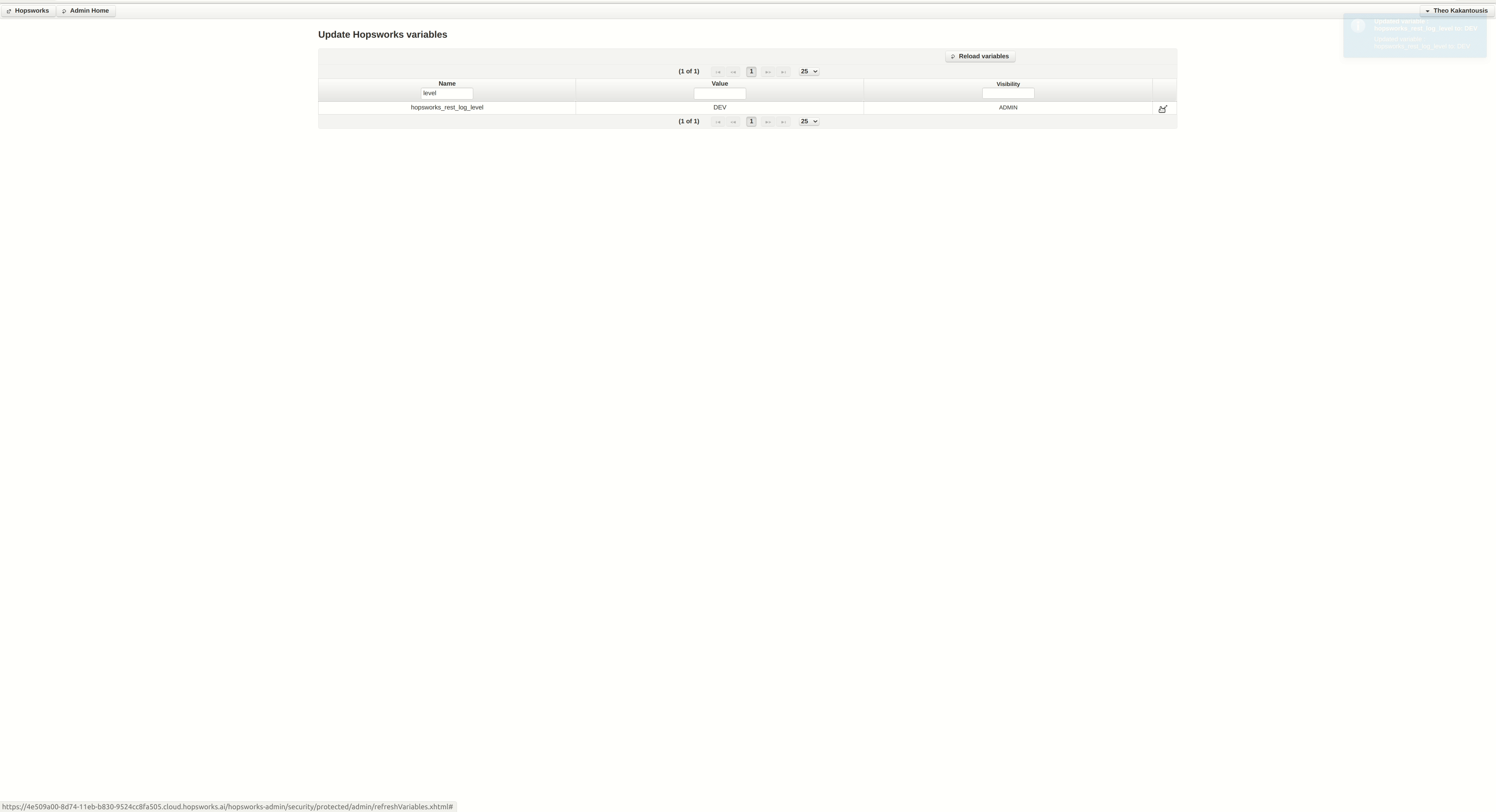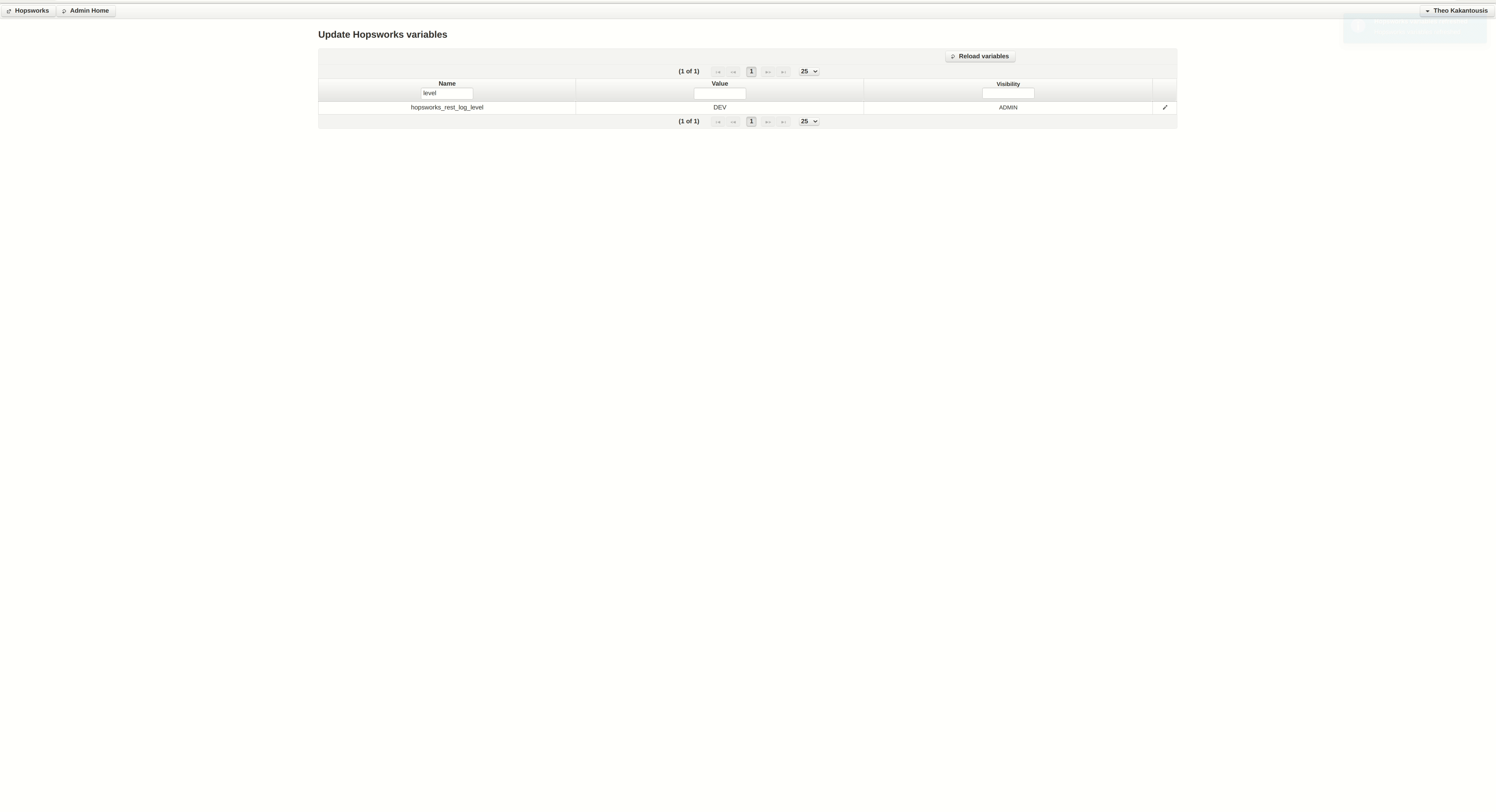
It seems something is wrong with the cluster setup in regards to running Python jobs. We can get some more logs in the UI by chancing the log level. You can do so by clicking the Admin option under your profile (top-right), then Edit Variables and then following the instructions in the gif that is attached.
Sorry about the error, I was testing the notebook on Hopsworks 2.2 where this issue has been fixed. Instead of Python, the same notebook works if you select Spark job type. It this case, it will be Spark that will insert the Pandas df in the feature group, there will be no additional ingestion job.