Hi,
I have followed the example provided by hopsworks.
Storage Connector for AWS -S3 added and below code is executed for pyspark.
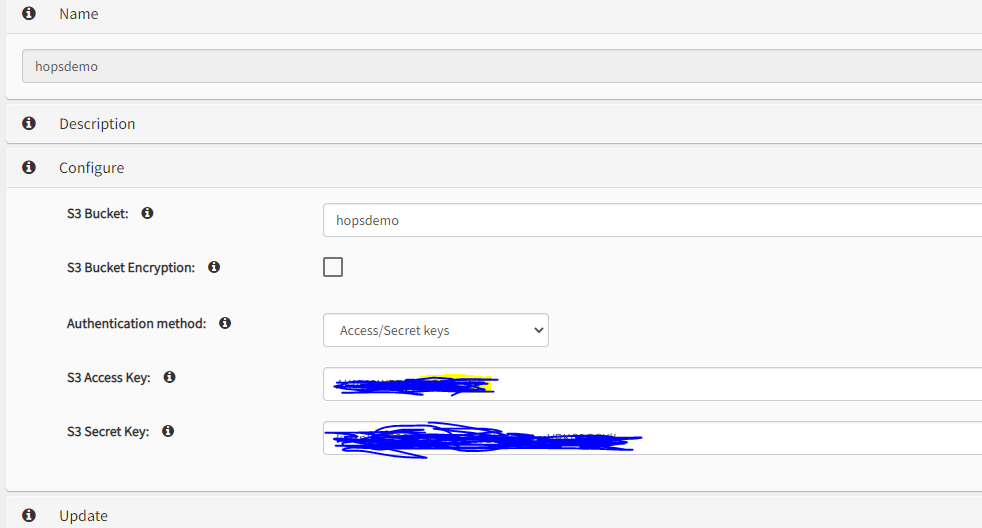
sc = fs.get_storage_connector(“hopsdemo”)
df = spark.read.csv(“s3a://” + sc.bucket + “/hopsdemo.csv”, header=True, inferSchema=True)
counterparty_fg = fs.create_feature_group(name=“hopsdemo_fg”,
version=1,
description=“On-demand FG with counterparty data”,
primary_key=[“customer_id”],
time_travel_format=None,
statistics_config={“enabled”: True, “histograms”: True, “correlations”: True, “exact_uniqueness”: True})
counterparty_fg.save(df)
But there is an error
: java.nio.file.AccessDeniedException: s3a://hopsdemo/hopsdemo.csv: getFileStatus on s3a://hopsdemo/hopsdemo.csv: com.amazonaws.services.s3.model.AmazonS3Exception: Forbidden (Service: Amazon S3; Status Code: 403; Error Code: 403 Forbidden; Request ID: VRT43XH7S6RYQ76Y; S3 Extended Request ID: GxBuxAWuXrtdP8/1gWmVkDFoMjeoIVx+d1hrkrCdiSt369K4LPUR4c8JMyXRQyM9wb/FvHYSiqk=), S3 Extended Request ID: GxBuxAWuXrtdP8/1gWmVkDFoMjeoIVx+d1hrkrCdiSt369K4LPUR4c8JMyXRQyM9wb/FvHYSiqk=:403 Forbidden
Can you please help on how to add cluster wide IAM role on instance profile of hopsworks demo cluster.
Thanks,
Pratyusha