Hi,
using hsfs on my local machine I created a feature group and save a dataframe with the following code:
fg_target = fs.create_feature_group(
name="target",
version=1,
description="customerID, Churn",
online_enabled=False,
time_travel_format=None,
primary_key=['customerID'],
statistics_config=None
fg_target.save(data_prep.target_table)
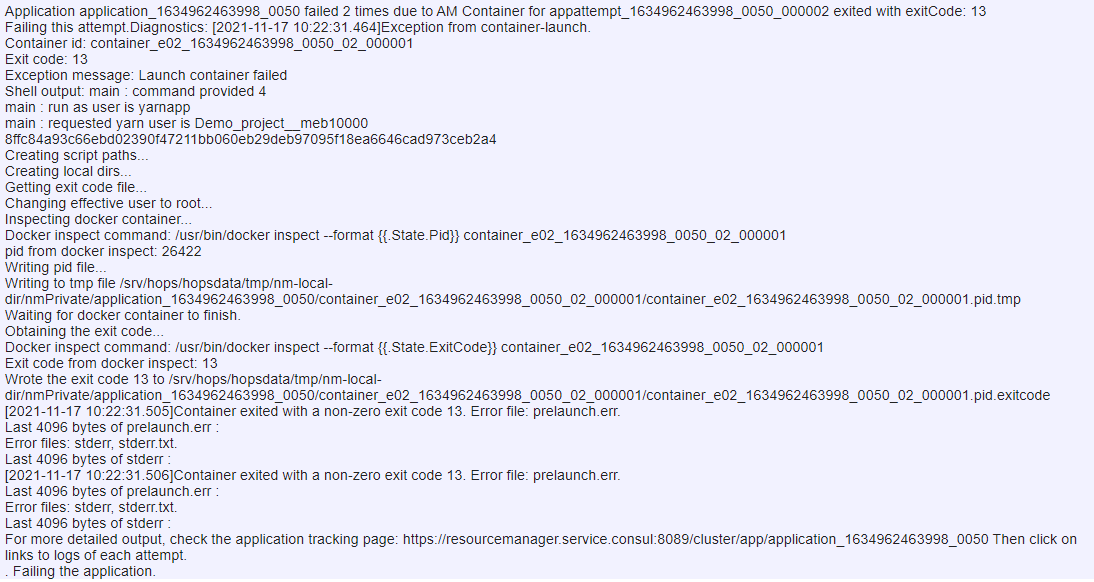
The PySpark Job is successfully created, however it fails after ca. 30 seconds.
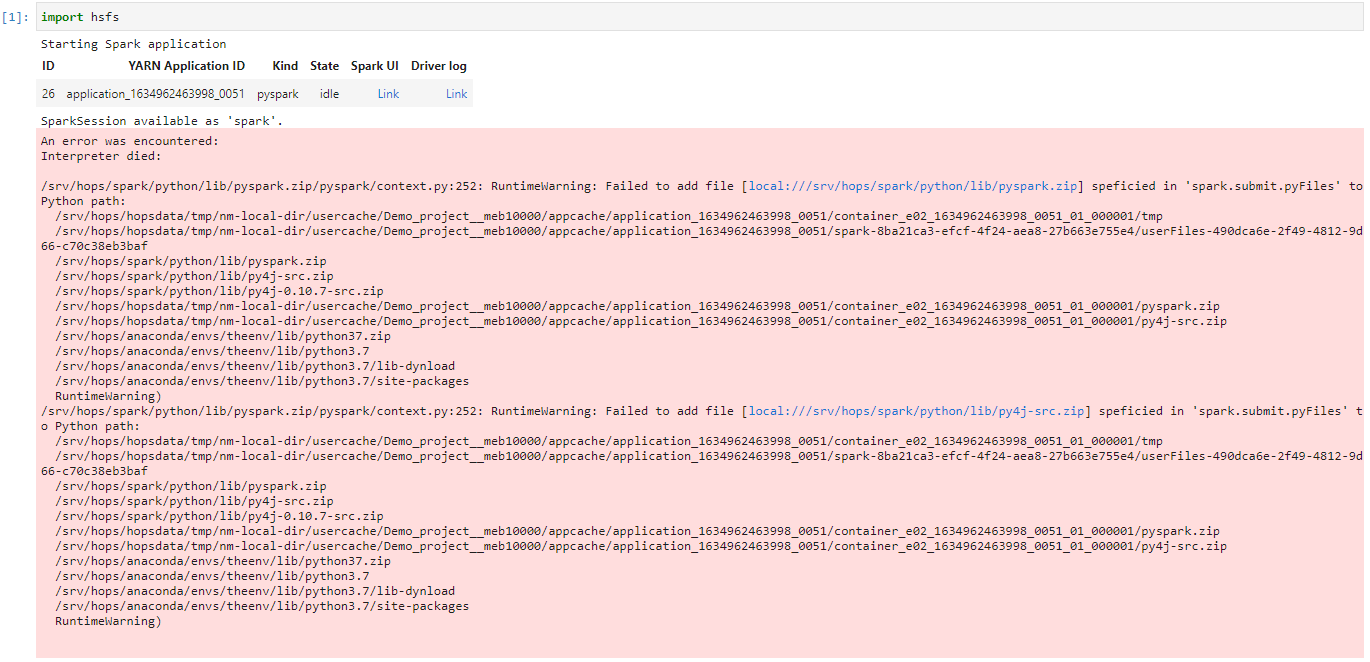
Similarly, PySpark Jupyter notebook crashes just after executing “import hsfs” command:
What could be the source of this problem? The Hopsworks version we use is 2.2, hsfs library 2.2.21.
Regards
Kristof
Hi @Krzysztof
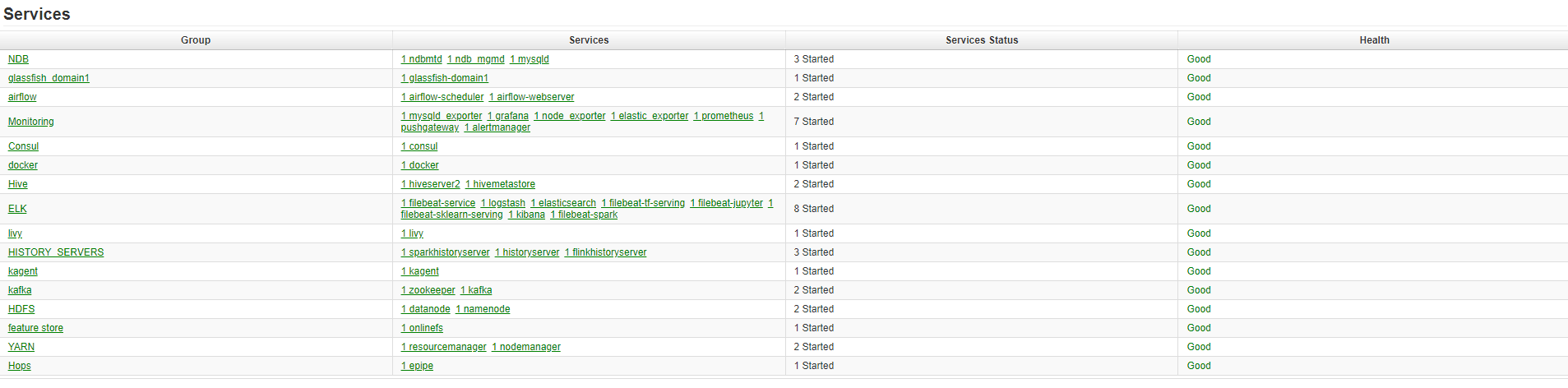
The import failure logs at the second screenshot do not look good. Could you please make sure every service is up and running?
To do so, assuming you are an Administrator, go to the traditional Hopsworks UI at https://IP_ADDRESS/hopsworks, click on your email at the top right corner and then Services. All services should be green.
Kind regards,
Thank you @antonios for your reply.
In the meantime we have fully reinstalled Hopsworks (it is single node on-premises installation on Ubuntu 18.04 LTS). The errors however are still valid. I have checked the services, as you suggested, everything seems correct:
Is there any procedure to verify that the services are up and running? Is there any other way to check logs for services?
Regards,
Kristof
Hi @Krzysztof!
When you installed hopsworks did you use the installer script? (https://repo.hops.works/installer/latest/hopsworks-installer.sh or https://repo.hops.works/installer/latest/hopsworks-cloud-installer.sh) Also are you still on hopsworks 2.2 after the reinstall?
Best regards, Robin
Hi @Robin_Andersson
After the reinstall have upgraded Hopsworks to 2.4 with use of the following script:
https://raw.githubusercontent.com/logicalclocks/karamel-chef/master/hopsworks-installer.sh
Kind regards
Krzysztof
Hi @Krzysztof, we don’t recommend installing hopsworks using the master branch as it may be unstable in periods. Can you instead use https://repo.hops.works/installer/latest/hopsworks-installer.sh?
The above will install hopsworks 2.3. But also the 2.4 installation script should be ready now, which you can find at https://raw.githubusercontent.com/logicalclocks/karamel-chef/2.4/hopsworks-installer.sh
Best regards,
Robin
Hi @Robin_Andersson,
OK, we will reinstall Hopsworks from one of the links you provided, hopefully it will work.
Thank you,
Krzysztof
Great @Krzysztof! Can you also let me know which one you choose? And I’ll deploy it to and make sure everything is working correctly.
Sure, we will install 2.4 version:
https://raw.githubusercontent.com/logicalclocks/karamel-chef/2.4/hopsworks-installer.sh
Kind regards,
Krzysztof
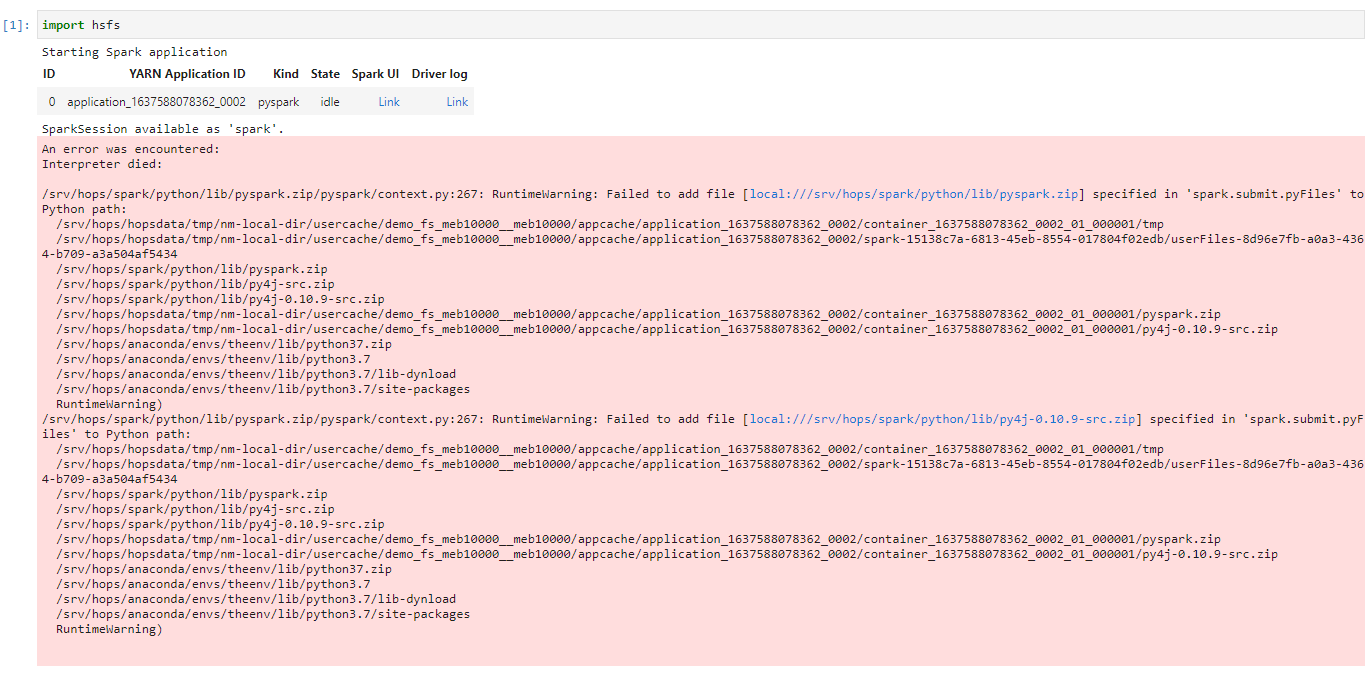
Hi @Robin_Andersson, we have reinstalled Hopsworks to version 2.4 from the link I sent previously - unfortunately I have the same error:
During installation all packages have been successfully installed… Do you have any idea on what can be the reason for such behaviour?
Kind regards
Krzysztof
Thanks @Krzysztof I’m looking into it now. To make sure it’s not a hardware problem, can you let me know how much total and free RAM you have on the machine? Also if you switch to the Python kernel in your notebook I guess it works to import hsfs?
We have 33 GB RAM memory, 150 GB disk size and 8 CPUs on our machine.
In fact if I switch to “pure” Python kernel the cell “import hsfs” does not start at all - it attempts to start but stops without any warning or error being shown below the cell. This is how it looks after execution of whole notebook:
It seems to me that the issue is just the HSFS library as any other command is working both on Python and PySpark kernel.
Kind regards,
Krzysztof
Thanks @Krzysztof!
That’s really helpful. Can you show me the configuration you used to start Jupyter with? You will find it if you go back to Hopsworks. I would like to try and see what happens if you increase the Spark driver memory and try to import hsfs in the PySpark kernel again.
I have used the default configuration - please find it attached below:
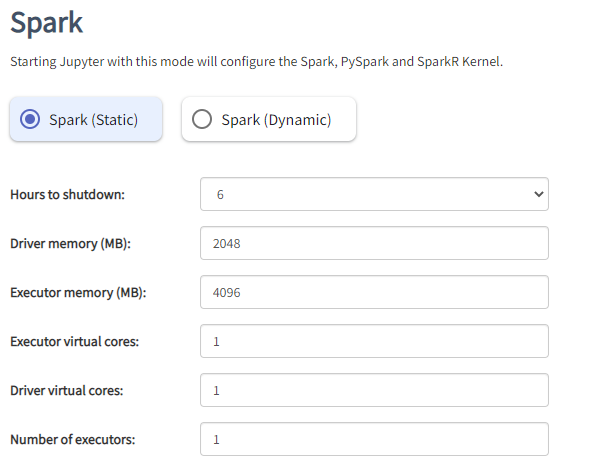
Kind regards,
Krzysztof
Hi @Robin_Andersson,
I attach the stdout.log file for the PySpark job, which fails. Maybe that can help a little.
Processing: stdout.log…
stdout.zip (1.2 KB)
Kind regards,
Krzysztof
Thanks @Krzysztof! Can you also send the stderr?
Also does it work to run Spark applications that don’t utilize hsfs? Like SparkPI for example: spark/SparkPi.scala at master · apache/spark · GitHub
Sure, stderr is attached. However, I don’t think it will help…
stderr.zip (288 Bytes)
The applications that don’t utilize hsfs (2.4.5 in my case) do work - both Python and Scala (PI value computation) didn’t fail.