When I try to create a new feature store, I get the error “MySQL JDBC Update Statement failed”. I also got an error about Hive tables not getting created before. I was previously able to create a feature store, but deleted it because I forgot to make online available. However now I can’t create any feature stores.
Thanks,
Sarah
Hi Sarah,
each project on Hopsworks comes with its own feature store, so is it that you cannot create new projects with the feature store service enabled?
However, it sounds more like you speaking about creating feature groups within a feature store? If that’s the case, can you provide some details about how you are trying to create them, e.g. is it a Cached Feature Group or On-Demand Feature group, through the UI or through HSFS client libraries?
Also, where is your Hopsworks instance deployed, through hopsworks.ai or is it a manual installation? So I can try and reproduce your issue.
Thanks!
Yes sorry I actually meant create a feature group inside of a feature store. I have a hopsworks.ai cluster on AWS with all services enabled, including Feature Stores and Online Feature Store.
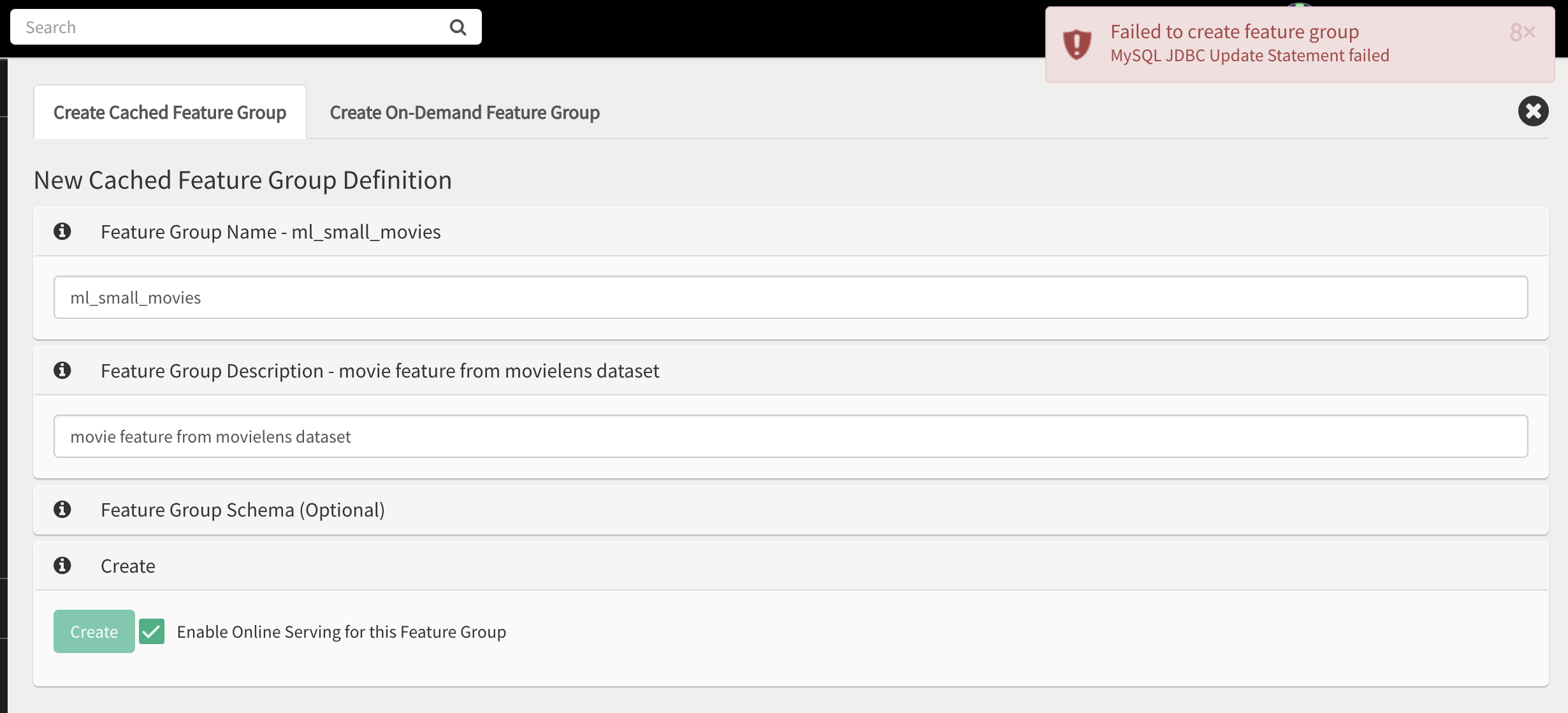
When I try to create a feature group, I get the following error:
Since the UI wasn’t working, I also tried to connect to the feature store locally using the Python API, but when I run import hops.featurestore as fs I get the error:
ImportError: cannot import name '_get_online_feature_store_password_and_user' from 'hops.featurestore_impl.online_featurestore'
Thanks for the additional info!
To create a feature group in the online feature store, a schema is required, e.g. you have to specify the features and their types. The error is not very informative, I have to admit.
Creating an offline-only feature group without schema should be possible.
Additionally, there seems to be a bug, and the offline part of the feature group gets created, whereas the online part fails afterwards, but the whole operation should fail from the start.
I created a Ticket for that on our side to fix this and improve the error message.
So I recommend you to clean up this half created feature group. You can do so by going to the “Data Sets” browser service, go to the Featurestore.db directory and delete the directory of the feature group you tried to create, which should be called ml_small_movies_1:
With respect to your second problem, with version 2.0 of Hopsworks we started to deprecate the hops.featurestore module in favour of an all new client called HSFS which should be much more intuitive to use and comes with much more functionality, you can find documentation about it here: https://docs.hopsworks.ai/.
Are you trying to connect from you local Python environment on your machine or from a Jupyter Notebook within Hopsworks?
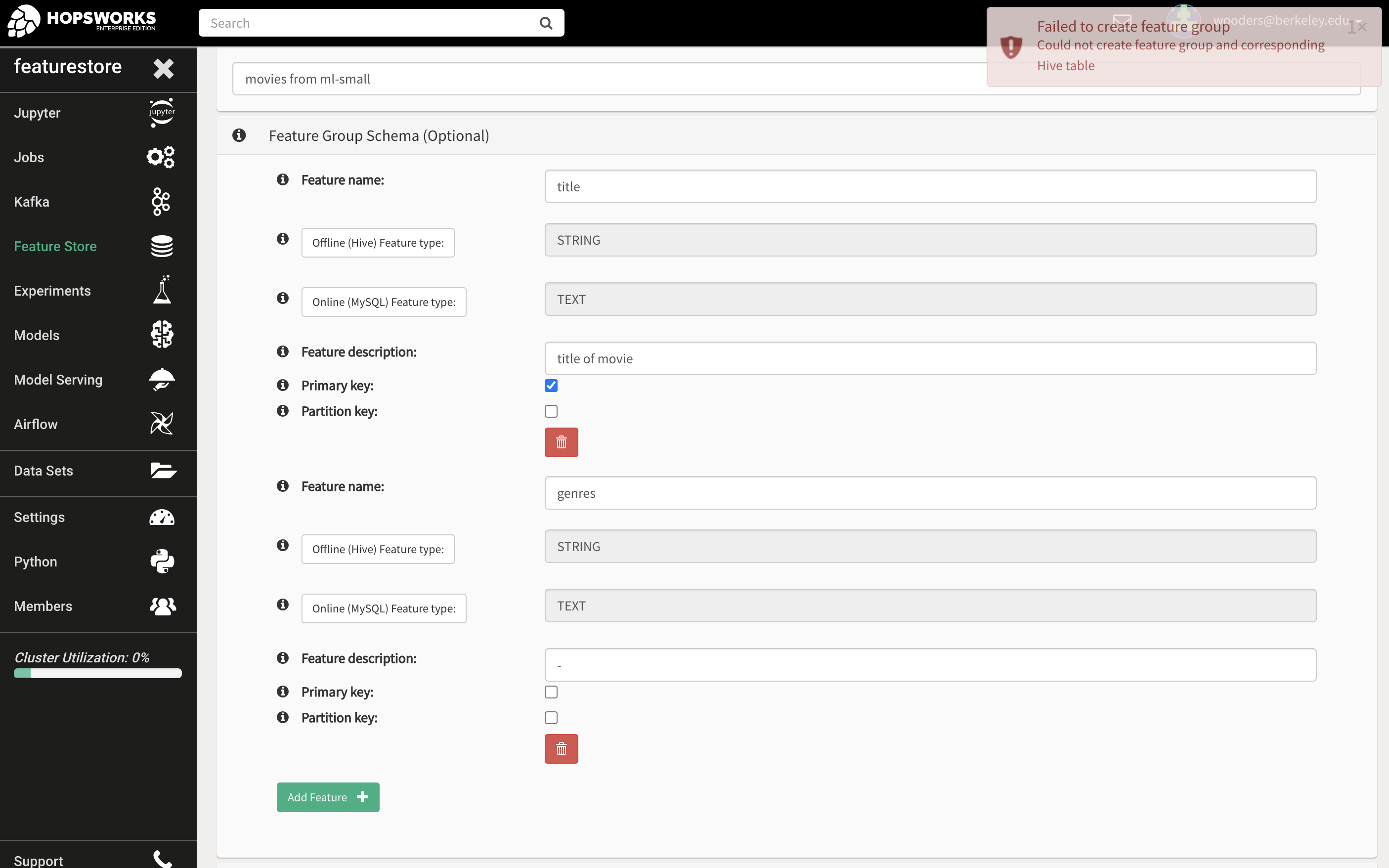
I tried to create a schema along side creating the feature-store, however still got an uninformative error:
I also tried removing everything inside “Datasets/Featurestore.db”, however still got the same error.
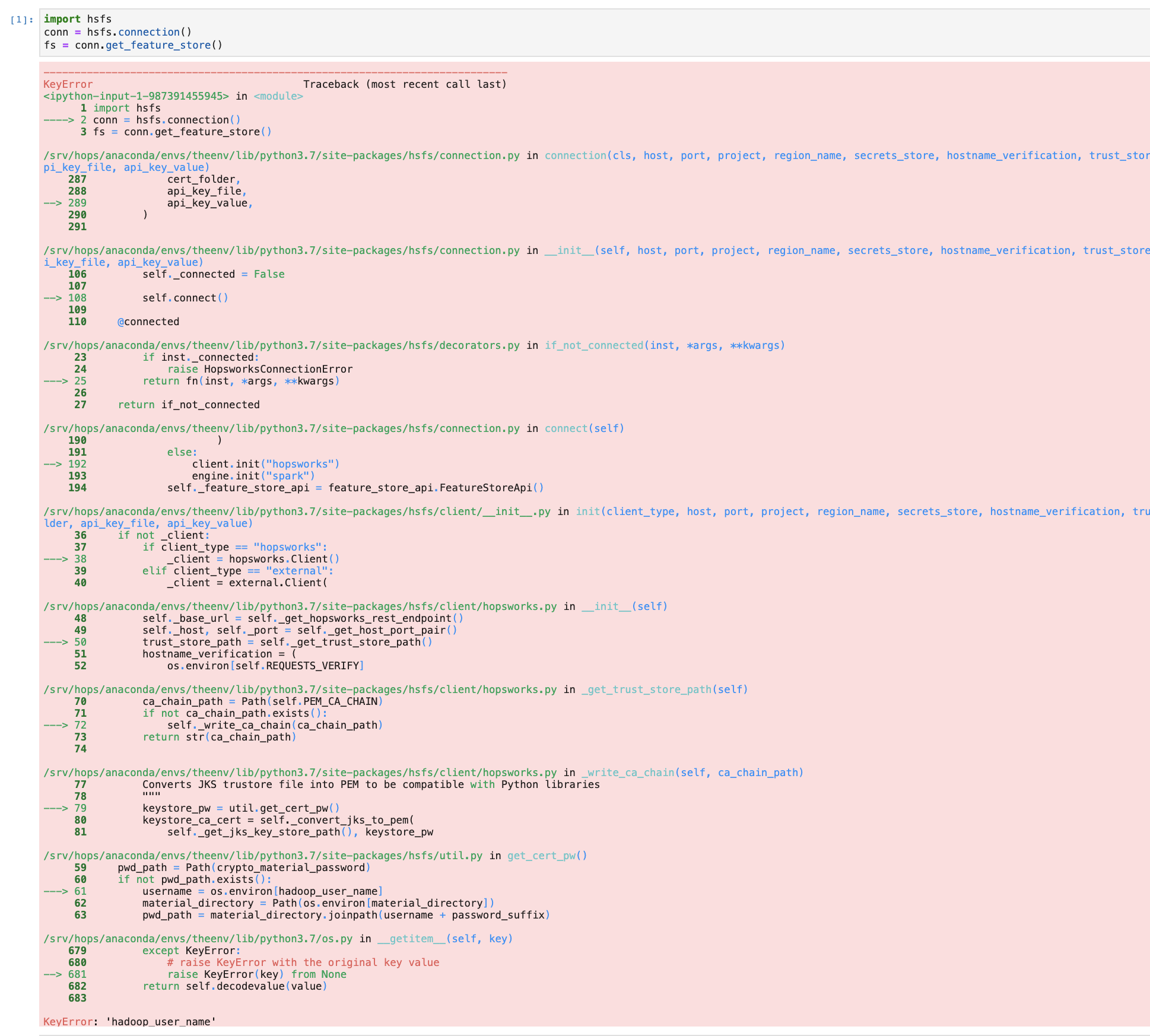
I tried connecting from both a local environtment and from Hopsworks. When I try to connect form Hopsworks Jupyterlab, I get the error:
For connecting from a local python environtment, I tried to follow the documentation here https://docs.hopsworks.ai/generated/project/, however my the only host URL I have is a hopsworks URL (not an EC2 instance), and my API key from Hopsworks is only one value, not a tuple. I tried a couple combinations to try to match the documentation, but get the error ValueError: Invalid port ''..
Please let me know what I’m doing wrong, as I’m very confused why my API keys and URL don’t match the documentation. Thanks!
Hi!
So first about connecting from local Python: The single value API Key is correct, in the documentation it’s just Black Code Formatting, so that means the parenthesis around the two strings will concatenate them, it’s just split this way to fit on a 88 char line length.
You can just replace the EC2 URL with your hopsworks.ai instance url. You would use the EC2 url if your Hopsworks instance is a manual installation.
Since you’re using Hopsworks.ai, please make sure you have enabled the Feature Store services on Hopsworks.ai to be reachable from the internet:
For a precise guide, please refer to the documentation here. Let me know if that gets you further.
For connecting from Hopsworks Jupyter service, can you try again with a PySpark kernel? On Hopsworks we are using Spark as an execution engine.
Now about your Schema error, the Datatype text is saved as a Binary Blob which cannot be used as a primary key. You should either use a fixed length char type or an int Numeric column as primary key.