Hi,
Can you please guide me on where I am going wrong with python code mentioned in my previous message. I am working on establishing the connection with any database and trying to pull some data from the tables.
with pyspark code:
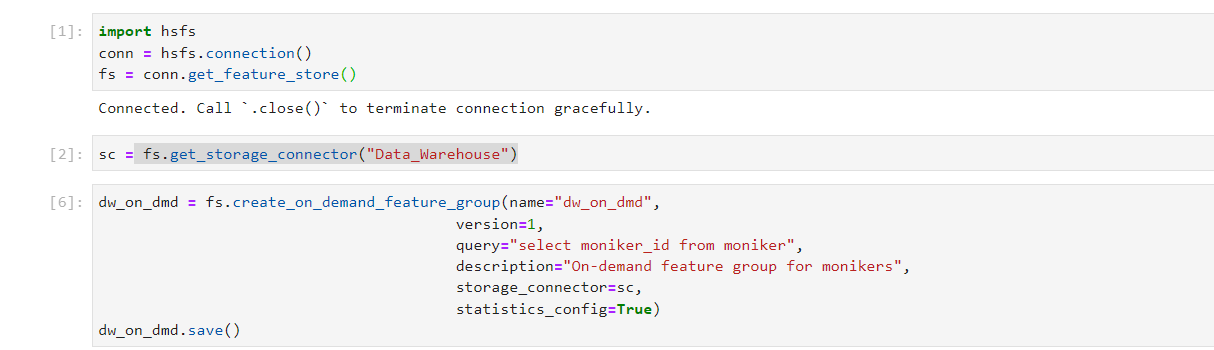
import hsfs
connection = hsfs.connection()
fs = connection.get_feature_store()
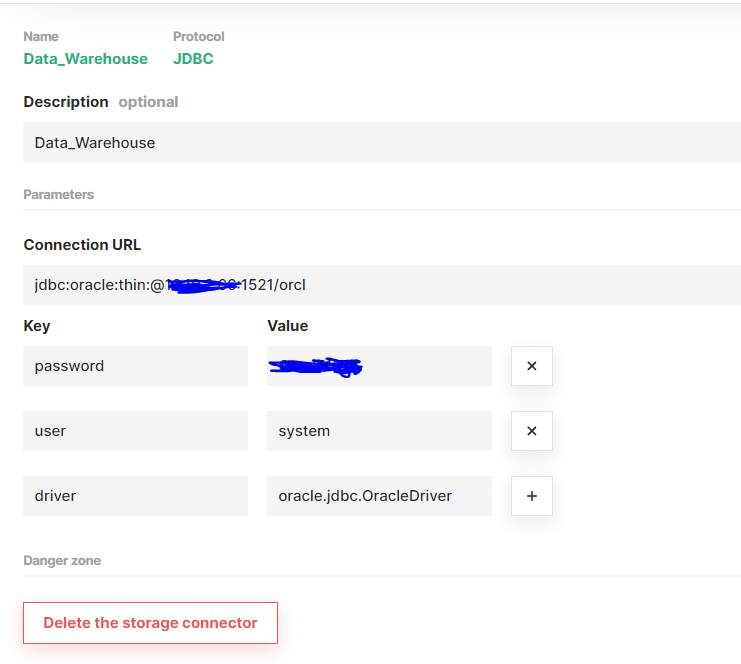
dwh = fs.get_storage_connector(‘OracleConnection’)
dwh_df = fs.create_on_demand_feature_group(
name=‘dwh_df’,
version=None,
query=“select * from dual”,
description=‘On-Demand data from Oracle’,
storage_connector = dwh,
statistics_config = True
)
dwh_df.save();
Error :
An error was encountered:
An error occurred while calling o155.load.
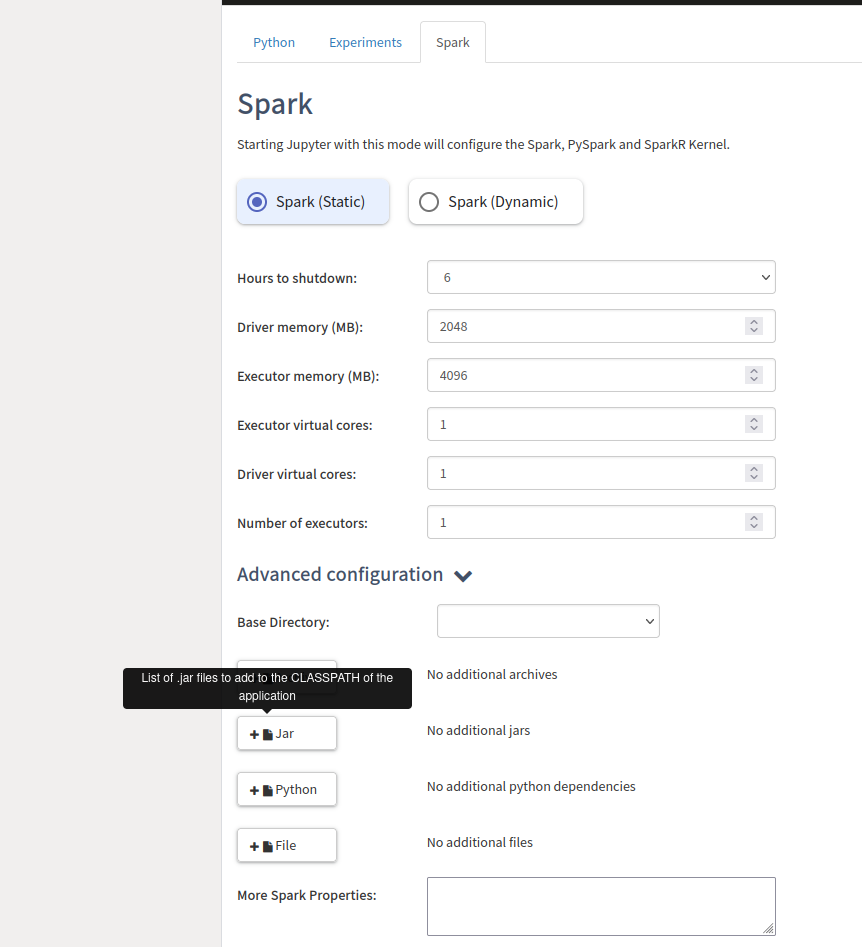
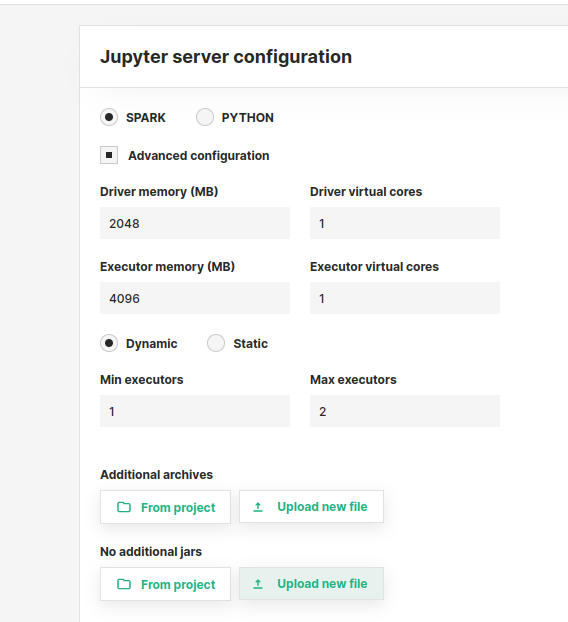
: java.lang.ClassNotFoundException: oracle.jdbc.OracleDriver
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at org.apache.spark.sql.execution.datasources.jdbc.DriverRegistry$.register(DriverRegistry.scala:46)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.$anonfun$driverClass$1(JDBCOptions.scala:102)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.$anonfun$driverClass$1$adapted(JDBCOptions.scala:102)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.(JDBCOptions.scala:102)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.(JDBCOptions.scala:38)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:32)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:354)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:326)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$3(DataFrameReader.scala:308)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:308)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:226)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Traceback (most recent call last):
File “/srv/hops/anaconda/envs/theenv/lib/python3.7/site-packages/hsfs/feature_group.py”, line 1365, in save
self._feature_group_engine.save(self)
File “/srv/hops/anaconda/envs/theenv/lib/python3.7/site-packages/hsfs/core/on_demand_feature_group_engine.py”, line 26, in save
feature_group, “read_ondmd”
File “/srv/hops/anaconda/envs/theenv/lib/python3.7/site-packages/hsfs/engine/spark.py”, line 85, in register_on_demand_temporary_table
on_demand_fg.storage_connector._get_path(on_demand_fg.path),
File “/srv/hops/anaconda/envs/theenv/lib/python3.7/site-packages/hsfs/storage_connector.py”, line 754, in read
return engine.get_instance().read(self, self.JDBC_FORMAT, options, None)
File “/srv/hops/anaconda/envs/theenv/lib/python3.7/site-packages/hsfs/engine/spark.py”, line 444, in read
.load(path)
File “/srv/hops/spark/python/lib/pyspark.zip/pyspark/sql/readwriter.py”, line 210, in load
return self._df(self._jreader.load())
File “/srv/hops/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py”, line 1305, in call
answer, self.gateway_client, self.target_id, self.name)
File “/srv/hops/spark/python/lib/pyspark.zip/pyspark/sql/utils.py”, line 111, in deco
return f(*a, **kw)
File “/srv/hops/spark/python/lib/py4j-0.10.9-src.zip/py4j/protocol.py”, line 328, in get_return_value
format(target_id, “.”, name), value)
py4j.protocol.Py4JJavaError: An error occurred while calling o155.load.
: java.lang.ClassNotFoundException: oracle.jdbc.OracleDriver
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at org.apache.spark.sql.execution.datasources.jdbc.DriverRegistry$.register(DriverRegistry.scala:46)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.$anonfun$driverClass$1(JDBCOptions.scala:102)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.$anonfun$driverClass$1$adapted(JDBCOptions.scala:102)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.(JDBCOptions.scala:102)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.(JDBCOptions.scala:38)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:32)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:354)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:326)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$3(DataFrameReader.scala:308)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:308)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:226)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Thanks,
Pratyusha