I find that HOPSWORKS can connect to a S3 server in the Feature Store menu, as shown below :
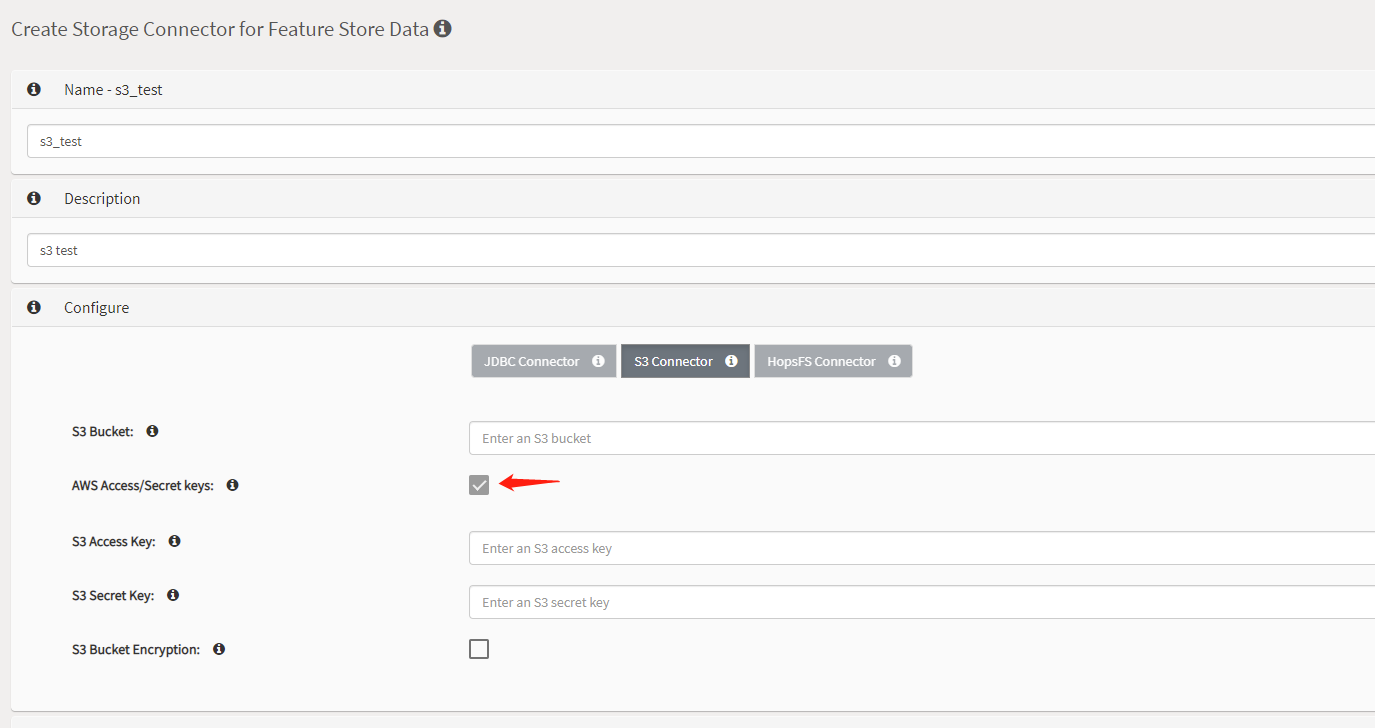
But I wonder if HOPSWORKS only supports connecting to AWS ? If I want to connect to another S3 server (such as MINIO), how should I do ?
I find that HOPSWORKS can connect to a S3 server in the Feature Store menu, as shown below :
But I wonder if HOPSWORKS only supports connecting to AWS ? If I want to connect to another S3 server (such as MINIO), how should I do ?
Hej Freeman,
As far as we know, it only works directly with AWS S3, since we didn’t try this before and we have no experience with MINIO.
If you have a specific problem we might be able to help you, but adding MINIO support is not on our current roadmap.
Alex
Hi @Alex ,
I still have some questions about Storage Connector.
What should I do if I want to connect to S3 in AWS? Do I need to deploy HOPSWORKS on AWS?
If I install HOPSWORKS on the local servers (On-Premise), how do I connect to AWS? Do I have to install the Feature Store on my local servers first?
Are there any relevant documents on the official website? Looking forward to your reply.
Hej @Freeman,
So if you deploy your cluster in AWS you can use:
https://docs.hopsworks.ai/feature-store-api/latest/integrations/storage-connectors/s3/
If you deploy your cluster on prem and want to connect to AWS, you need to change the authentication method and use access key (instead of temporary credentials) and secret from the same storage connector view:
Hope this answers your question.
Regards,
Alex
Hi @Alex ,
Thank you very much for your reply.
Could you tell me how HOPSWORKS works with S3 data? When I plan to train a model by using data from S3, what happens in this process? Will HOPSWORKS copy the data from S3 to HDFS (Data Sets) first? If not, how does HOPSWORKS read the data in AWS S3 ? If it is connected to AWS directly , does network bandwidth affect the speed of model training?
Hej @Freeman,
Storage connectors are used together with on demand feature groups:
https://docs.hopsworks.ai/feature-store-api/latest/generated/on_demand_feature_group/
When planning to use an external storage source, you would define a on demand feature group and you would probably then derive cached feature groups and eventually a training dataset to use in your model training.
On demand feature groups are not saved in the Featurestore. They will always be pulled from the external sources whenever a job would read them. If you want them cached in the Hopsworks Featurestore you should create a cached feature group using the on demand feature group. This one will now be stored in the Featurestore and when a job would use it, it would not incur additional traffic to your S3 bucket.
Second, most likely when training you would need your data in a particular format, and that is where the training dataset comes to help as you have the option to materialize all the necessary features in the format required by your model training framework. These training datasets are stored in the Featurestore (Hopsworks).
Hope this answers some of your questions.
Regards,
Alex
Hej @Freeman,
As a followup, feel free to take a look at our examples on usage of S3 and our Featurestore:
Also what I missed in my previous answer, training datasets can also be saved/read from S3 with a Storage Connector:
https://docs.hopsworks.ai/feature-store-api/latest/generated/api/training_dataset_api/
But once again, remember that when you go through a Storage Connector, be it feature group or training dataset, we do not cache any data, so we will always go to the S3 bucket.
Regards,
Alex

