I’m getting the following error when trying to create a dataset with ADLS connector when running in a Jupyter Notebook in my local machine.
storage = fs.get_storage_connector("connector-name")
td = fs.create_training_dataset(
name="records_td3",
description="Dataset to train some model",
seed=12,
version=1,
storage_connector=storage,
)
td.save(query)
2022-06-02 21:24:25,852 ERROR canvass_poc_fs,records_td3_1_create_td_02062022212402,1510,application_1645026761274_0674 ApplicationMaster: User application exited with status 1
2022-06-02 21:24:19,824 INFO canvass_poc_fs,records_td3_1_create_td_02062022212402,1510,application_1645026761274_0674 Version: Elasticsearch Hadoop v7.13.0-SNAPSHOT [ba4a70edaf]
2022-06-02 21:24:22,563 INFO canvass_poc_fs,records_td3_1_create_td_02062022212402,1510,application_1645026761274_0674 SessionState: Hive Session ID = 0aed9bc2-b93b-40df-b0da-fd4a36c4befc
2022-06-02 21:24:25,350 WARN canvass_poc_fs,records_td3_1_create_td_02062022212402,1510,application_1645026761274_0674 UsersGroups: UsersGroups was not initialized.
Traceback (most recent call last):
File "hsfs_utils-2.5.0.py", line 138, in <module>
create_td(job_conf)
File "hsfs_utils-2.5.0.py", line 86, in create_td
td.insert(
File "/srv/hops/anaconda/envs/theenv/lib/python3.8/site-packages/hsfs/training_dataset.py", line 233, in insert
td_job = self._training_dataset_engine.insert(
File "/srv/hops/anaconda/envs/theenv/lib/python3.8/site-packages/hsfs/core/training_dataset_engine.py", line 98, in insert
return engine.get_instance().write_training_dataset(
File "/srv/hops/anaconda/envs/theenv/lib/python3.8/site-packages/hsfs/engine/spark.py", line 351, in write_training_dataset
self._write_training_dataset_single(
File "/srv/hops/anaconda/envs/theenv/lib/python3.8/site-packages/hsfs/engine/spark.py", line 428, in _write_training_dataset_single
feature_dataframe.write.format(data_format).options(**write_options).mode(
File "/srv/hops/spark/python/lib/pyspark.zip/pyspark/sql/readwriter.py", line 1109, in save
File "/srv/hops/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py", line 1304, in __call__
File "/srv/hops/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 111, in deco
File "/srv/hops/spark/python/lib/py4j-0.10.9-src.zip/py4j/protocol.py", line 326, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o192.save.
: java.io.IOException: There is no primary group for UGI canvass_poc_fs__patrickr (auth:SIMPLE)
at org.apache.hadoop.security.UserGroupInformation.getPrimaryGroupName(UserGroupInformation.java:1530)
at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystemStore.<init>(AzureBlobFileSystemStore.java:136)
at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.initialize(AzureBlobFileSystem.java:108)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:3333)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:124)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:3382)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:3350)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:500)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:361)
at org.tensorflow.spark.datasources.tfrecords.DefaultSource.saveDistributed(DefaultSource.scala:106)
at org.tensorflow.spark.datasources.tfrecords.DefaultSource.createRelation(DefaultSource.scala:73)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:46)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:90)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:132)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:131)
at org.apache.spark.sql.DataFrameWriter.$anonfun$runCommand$1(DataFrameWriter.scala:989)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:989)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:438)
at org.apache.spark.sql.DataFrameWriter.saveInternal(DataFrameWriter.scala:415)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:293)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Jupyter notebook inside Hopsworks.ai (ML Demo) [15 trial]
When trying to run inside jupyter notebook from the Hopsworks Cloud ML Demo [15 days trial] I get similar message:
An error was encountered:
An error occurred while calling o278.save.
: java.io.IOException: There is no primary group for UGI demo_ml_patrickr__patrickr (auth:SIMPLE)
at org.apache.hadoop.security.UserGroupInformation.getPrimaryGroupName(UserGroupInformation.java:1530)
at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystemStore.<init>(AzureBlobFileSystemStore.java:136)
at org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem.initialize(AzureBlobFileSystem.java:108)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:3333)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:124)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:3382)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:3350)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:500)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:361)
at org.tensorflow.spark.datasources.tfrecords.DefaultSource.saveDistributed(DefaultSource.scala:106)
at org.tensorflow.spark.datasources.tfrecords.DefaultSource.createRelation(DefaultSource.scala:73)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:46)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:90)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:180)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:215)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:176)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:132)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:131)
at org.apache.spark.sql.DataFrameWriter.$anonfun$runCommand$1(DataFrameWriter.scala:989)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:772)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:989)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:438)
at org.apache.spark.sql.DataFrameWriter.saveInternal(DataFrameWriter.scala:415)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:293)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
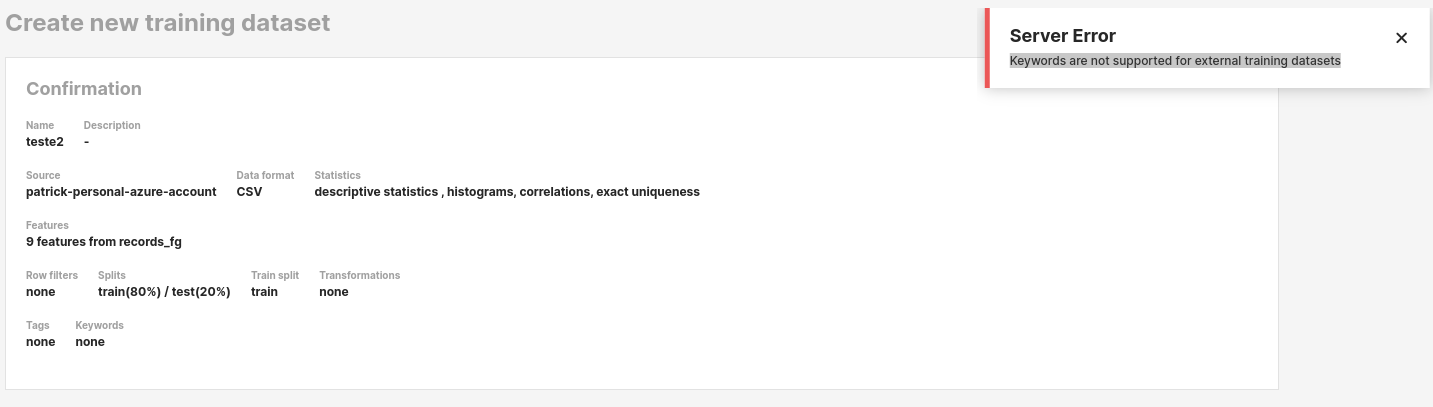
Hopswork web UI
When trying to create the dataset using the web UI I get the following error: