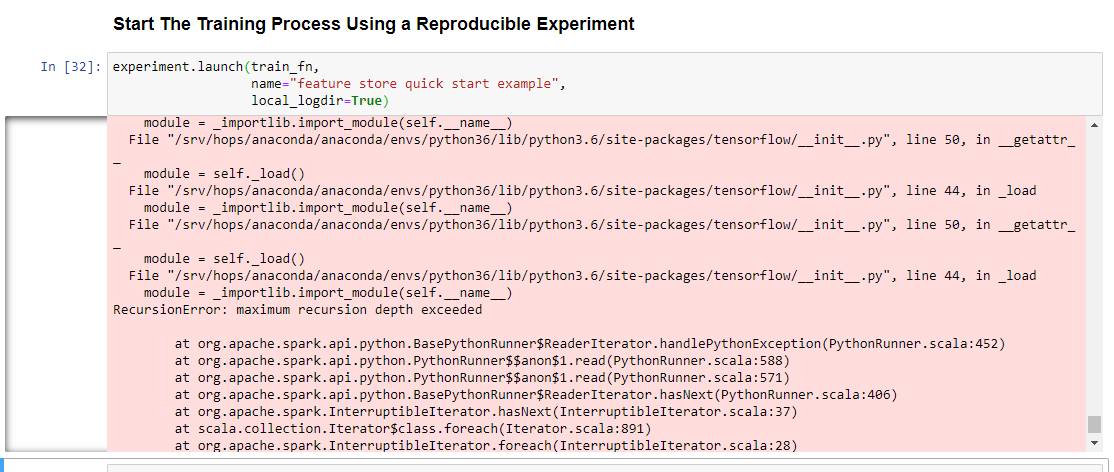
I’ve signed up on the 30-days free Hopsworks demo trial on hopsworks.ai and obtain an error in the Feature Store demo/tour in the Jupyter notebook “FeatureStoreQuickStart.ipynb”. The last cell which launches the ML experiment produces the following error “… RecursionError: maximum recursion depth exceeded …”.
Hey again! So I figured out the issue. The train_fn function in that example does not import tensorflow inside the function. Code that is executed outside the train_fn is run on the Spark Driver, so the import imported tensorflow on the driver and then it tried to serialize it over the network to the Spark Executors which failed. Hence the pickling issue.
I’ve signed up on the 30-days free Hopsworks demo trial on hopsworks.ai and obtain an error in the Feature Store demo/tour in the Jupyter notebook “FeatureStoreQuickStart.ipynb”.
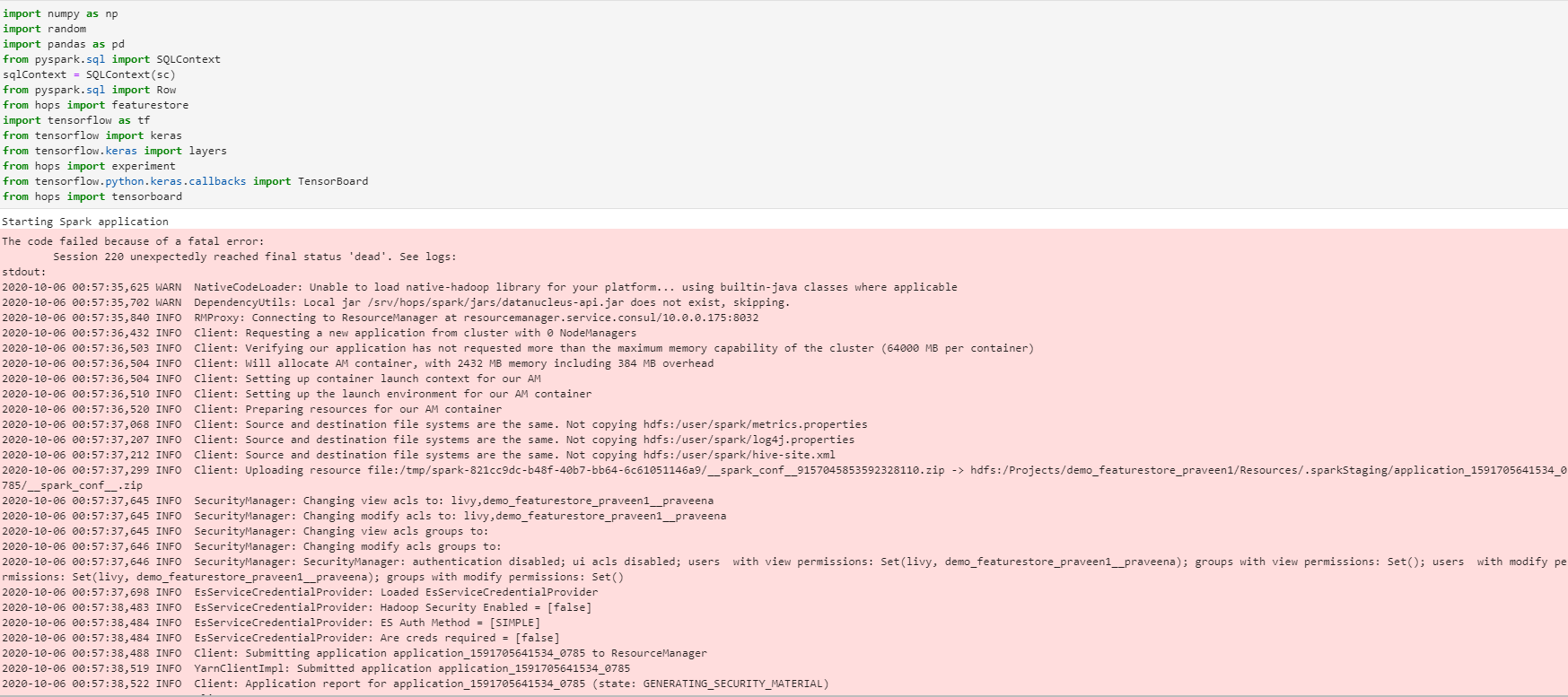
I’m getting an error while executing the 1st cell in jupyter notebook as below.
**YARN Diagnostics: ** [Tue Oct 06 00:57:38 +0000 2020] Application is added to the scheduler and is not yet activated. Skipping AM assignment as cluster resource is empty. Details : AM Partition = <DEFAULT_PARTITION>; AM Resource Request = <memory:2432, vCores:1, gpus:0>; Queue Resource Limit for AM = <memory:0, vCores:0, gpus:0>; User AM Resource Limit of the queue = <memory:0, vCores:0, gpus:0>; Queue AM Resource Usage = <memory:2048, vCores:1, gpus:0>; .
Some things to try: a) Make sure Spark has enough available resources for Jupyter to create a Spark context. b) Contact your Jupyter administrator to make sure the Spark magics library is configured correctly. c) Restart the kernel.
Thank you for reporting. I identified an issue with our trial cluster and resolved it. Could you try again? let me know if you encounter any more issues!
# read the data csv into a Spark DataFrame
from hops import hdfs
csv_path = hdfs.abs_path('') + 'Resources/' + 'my.csv'
raw_df = spark.read.csv(csv_path, header=True) # Use header False if needed
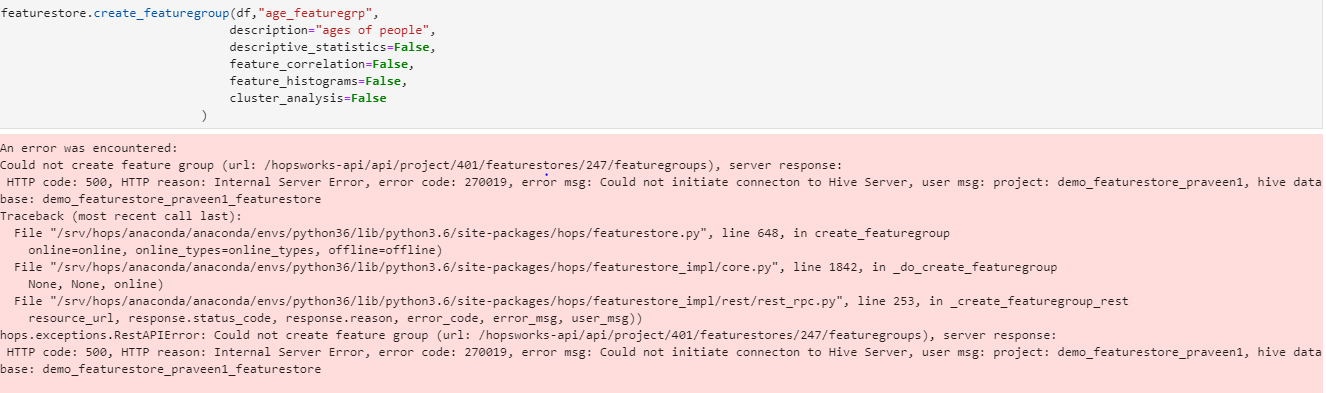
I tried to reproduce the the feature store write error but it worked fine for me. Could you run the FeatureStoreQuickStart.py up to the point when it writes to the feature store and confirm whether that works or not. In the meantime, I’ll look deeper into the logs.
UPDATE: I’m seeing some issues regarding your project in the logs. While I’m investigating how we can fix these, you could attempt to create a new project and run your code there.
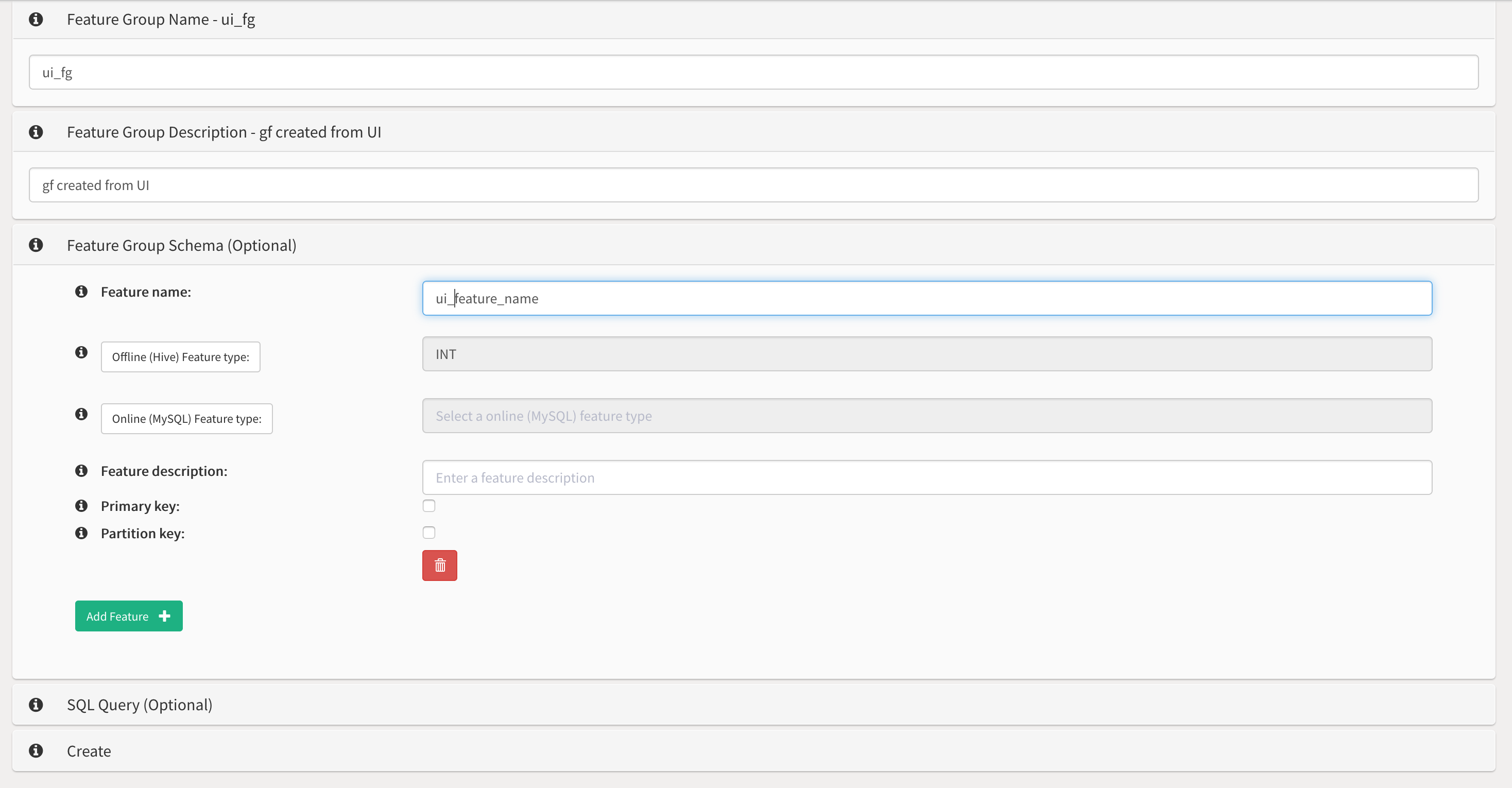
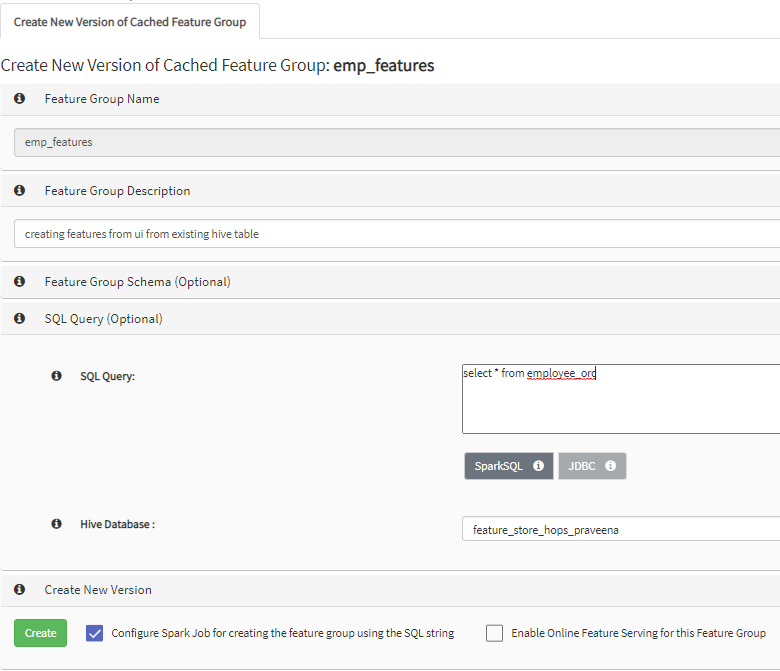
I am trying to create a feature group in feature store from UI from existing hive table which i have created in hops database but couldn’t find any relevant documentation on how to create it. Can you please suggest me how to do it.
Also please let me know if we can register features / create feature groups from UI directly rather than creating feature groups from Jupyter?
From hopsworks UI go to Feature Store --> Feature Group --> New. You can register new feature group with desired schema. If you want to create Feature Group from existing hive table then opt to on demand feature group tab where you can enter SQL query.
I have created feature group from Jupyter using below commands and its successful.
** featurestore.create_featuregroup(
houses_for_sale_features_df,
“houses_for_sale_featuregroup”,
description=“aggregate features of houses for sale per area”,
descriptive_statistics=False,
feature_correlation=False,
feature_histograms=False,
cluster_analysis=False
) **
But now what i want to try is, I have a table in hive db i.e., feature_store_hops_praveena.employee_orc and want to create a feature group on top of this table from UI rather than Jupyter and the feature group should show all the columns present inside table as features.
For this I tried giving SQL query but it is failing with below error 2020-10-15 22:45:20,403 ERROR feature_store_hops_praveena,create_featuregroup_emp_features_1602801879784,265,application_1591705641534_0866 FailoverProxyHelper: java.io.IOException: Failed on local exception: java.io.IOException: Couldn’t set up IO streams: java.lang.IllegalStateException: Shutdown in progress, cannot add a shutdownHook; Host Details : local host is: “ip-10-0-0-175/10.0.0.175”; destination host is: “ip-10-0-0-175.us-east-2.compute.internal”:8020;
2020-10-15 22:45:20,404 WARN feature_store_hops_praveena,create_featuregroup_emp_features_1602801879784,265,application_1591705641534_0866 HopsRandomStickyFailoverProxyProvider: HopsRandomStickyFailoverProxyProvider (1148816695) no new namenodes were found
And also before running the job its asking to pass “Input Arguments” which i’m not sure what to paas to it.
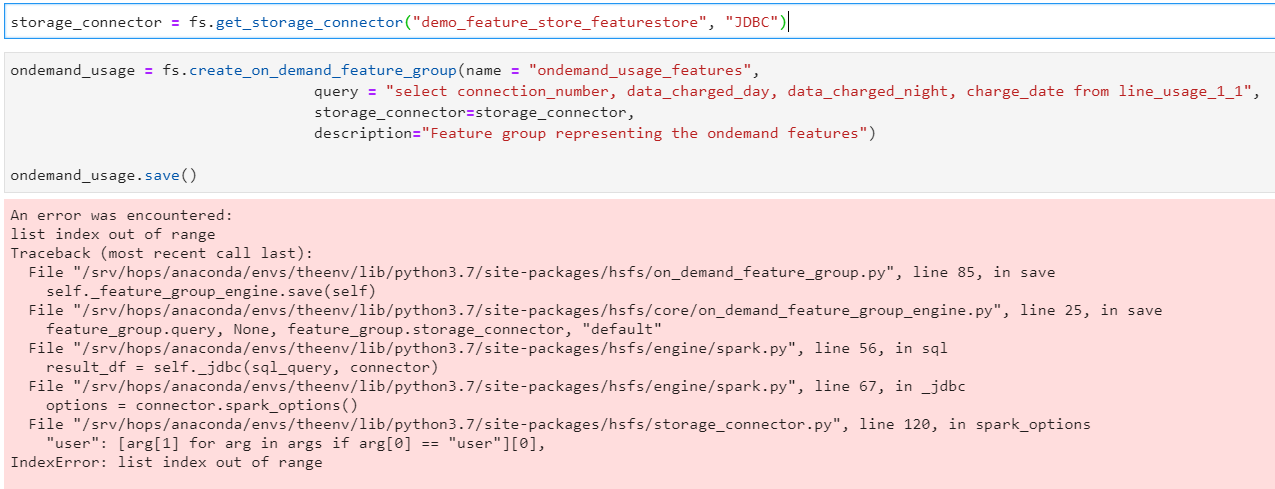
Same is the case while creating OnDemand features… The job is failing…
Which version of hopsworks are you using? Do you get the same error both for on demand and cached feature groups? Also did you provide schema when created feature group.
This says that your spark session is not active any more. Restart Jupyter kernel and it should will work. I will try to reproduce issue regarding on demand fg.