I’ve read all of your docs, scanned through the Github source code & etc.
However, I’m not clear if it is possible to deploy the Hopsworks Feature Store as a standalone from the rest of the application (Hopsworks).
Everything I’ve read so far points to it being tightly coupled to the rest of the Hopsworks ecosystem.
So:
Is it possible to deploy the Hopsworks Feature Store as a standalone, apart from the rest of the Hopsworks offering?
If yes, where can I find more info or documentation?
As context: We’re doing a feature parity between our internal feature management tools and other tools (open source, vendor) with the Hopsworks FS being one of those. The ability for it to be decoupled from the rest of the ecosystem, as a standalone, would be great if possible.
As the Feature Store is based on the Hopsworks platform, it is currently no possible to deploy it in isolation. Are there any specific components that you would like to avoid to deploy?
Yes, essentially all the other components. We already have a notebook (AI Notebooks / Kubeflow), training (Kubeflow), model store (internal), experiments (Kubeflow), & model serving solution (internal).
However, where we’re looking to improve is on the feature management side. I think there might be a good case for offering the Hopsworks Feature Store as a decoupled component.
I guess while we’re at it, some more questions if possible:
Is incoming data validated against a feature schema? If so, would you be able to provide detail (ie only data types, or actual schema validation)?
Are features immutable?
Would you be able to expand on consistency validation between offline/online features? ie what & how are you validating?
Regarding feature ingestion, what are the supported upserts/data sources?
The Feature Store relies on Spark to validate the schema. Spark is quite flexible, so that there is no strict validation on data types. Spark will try and match the data types, and fail if it can’t. However, you can use Deequ with Spark for actual data validation, allowing for more flexible rules.
No, you can use Hudi for incremental ingestion and updates. Currently, the Feature Store supports Copy-on-write semantics for this.
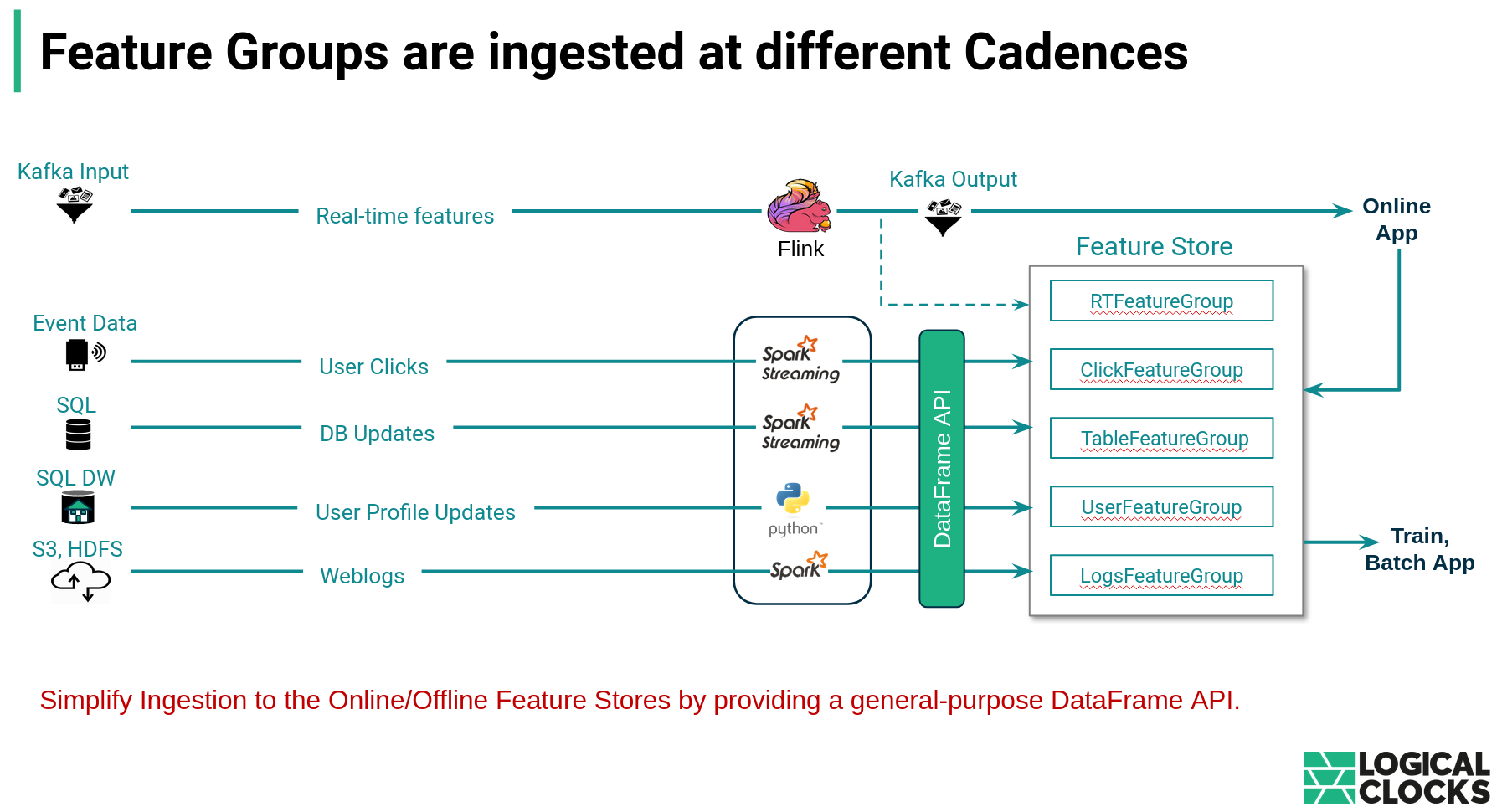
The Feature Store has a unified meta data layer between the offline and online feature store, keeping the meta data such as schema consistent. You can choose the default storage when ingesting feature groups and our dataframe based API ensures consistent ingestion to both. See also our Spark Summit Talk about this.
Depending on the execution engine you are going to use. If you use Spark, anything really that Spark can be read into a Spark Dataframe. We also support incremental ingestion using streaming applications to read from Kafka for example.
Since your setup is heavily based on KubeFlow, I recommend you watch our Webinar about the KubeFlow integration with Hopsworks.
Let me know if you have more questions.
#1 So, it sounds like there so no default feature schema validation when a new feature/feature group is ingested. Rather, the user can set their own “data validation rules”, which happens after a feature has already been ingested. This is through Deequ which triggers Spark.
^ correct?
#2 Okay.
#3 So, sounds like implicit consistency rather than a hard one?
#4 Couple of questions (feature ingestion) –
a) not all features need to be computed, so is Spark computation a hard requirement?
b) How exactly are features ingested into the FS? Is it an API, Kafka stream, direct connection, batch? Just trying to identify whether using BigQuery as a data source is supported.
In general there are two ways: (i) you can create the feature group through the UI by defining a schema with the features and their respective type, then appending data to it through the API with Spark, which will try to match the previously defined types, if it cannot match the types it will fail. Changing the schema or ingesting a new feature into an existing feature group will require you to create a new version of the group. Schemas can change between versions, but you cannot append features to an existing version of a feature group. This is to avoid breaking schema changes if a feature group is used in production. (ii) you ingest a dataframe as a feature group through the API, accepting the types that Spark infers, possibly using data validation with Deequ letting the ingestion fail if the rules are not satisfied. Subsequent ingestions will validate against this schema as before, again not being able to change the schema but just append/upsert new data.
Deequ is just another tool we provide within Hopsworks, so you can use it in any step of the pipeline.
Yes, metadata such as schemas or provenance data is consistent due to the single metadata layer.
a. Not sure I understand this question. If no feature transformations are required, the feature still needs to be read from a source and ingested into the feature store as a feature and you can use Spark as an engine to do so.
b. Depending on the cadence at which the data is to be ingested you have different tools available. Batch ingestion is available through our Dataframe API, which can be used in regularly scheduled jobs. Real-time ingestion can be done with Streaming applications using Spark Streaming or Flink applications.