We deployed Hopsworks in our cloud and it is run on an 8-core CPU, 32GB memory, 512GB disk VM.
When I started a PySpark Jupyter notebook and import hsfs. It failed to start an Spark application.
The error message is as follows:
Starting Spark application
The code failed because of a fatal error:
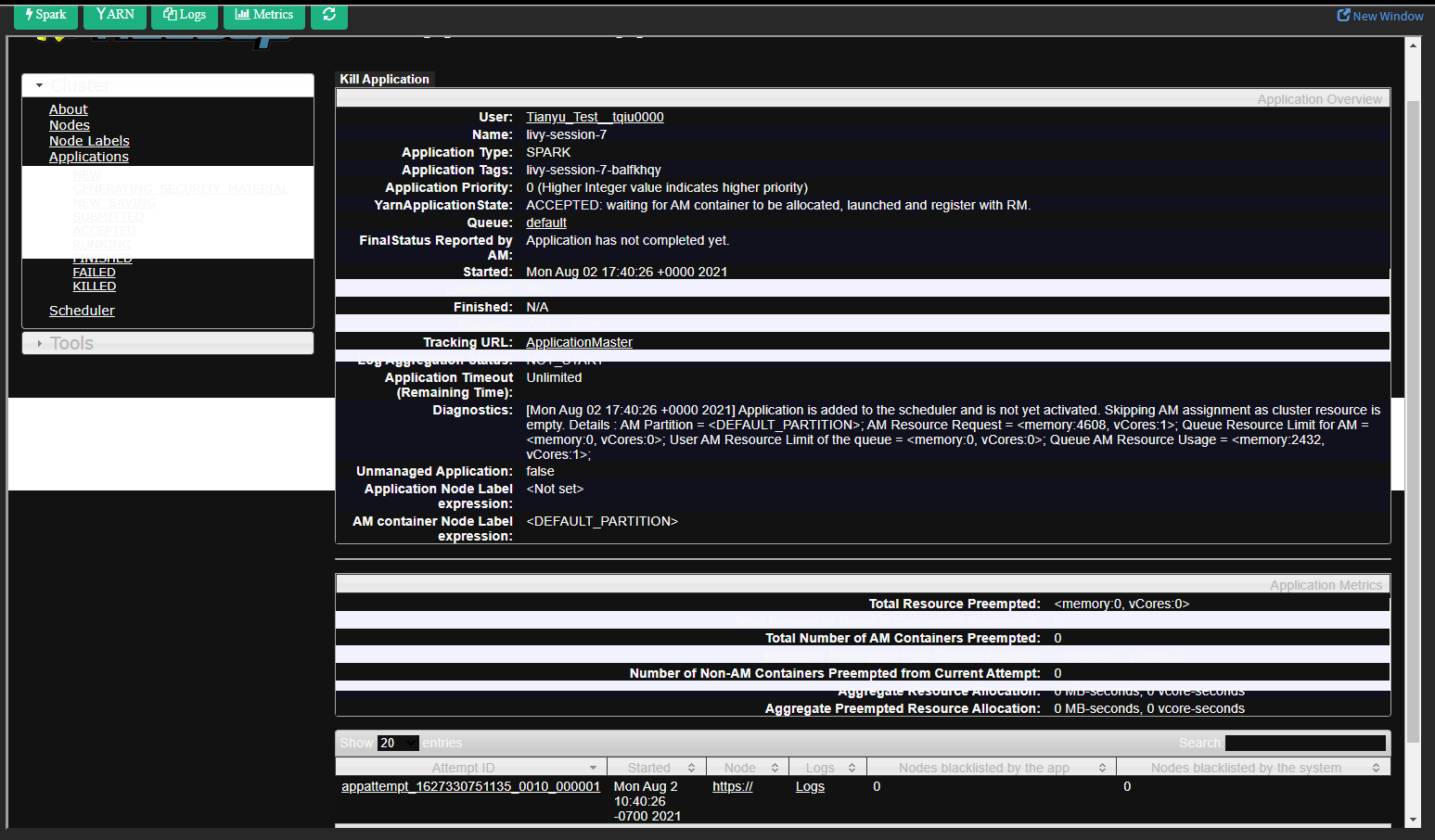
Session 3 unexpectedly reached final status ‘killed’. See logs:
stdout:
2021-07-30 21:25:21,923 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
2021-07-30 21:25:22,007 WARN DependencyUtils: Local jar /srv/hops/spark/jars/datanucleus-api.jar does not exist, skipping.
2021-07-30 21:25:22,149 INFO RMProxy: Connecting to ResourceManager at resourcemanager.service.consul/10.198.0.4:8032
2021-07-30 21:25:22,978 INFO Client: Requesting a new application from cluster with 0 NodeManagers
2021-07-30 21:25:23,052 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (64000 MB per container)
2021-07-30 21:25:23,053 INFO Client: Will allocate AM container, with 2432 MB memory including 384 MB overhead
2021-07-30 21:25:23,053 INFO Client: Setting up container launch context for our AM
2021-07-30 21:25:23,063 INFO Client: Setting up the launch environment for our AM container
2021-07-30 21:25:23,080 INFO Client: Preparing resources for our AM container
2021-07-30 21:25:23,899 INFO Client: Source and destination file systems are the same. Not copying hdfs:/user/spark/log4j.properties
2021-07-30 21:25:24,003 INFO Client: Source and destination file systems are the same. Not copying hdfs:/user/spark/hive-site.xml
2021-07-30 21:25:24,011 INFO Client: Source and destination file systems are the same. Not copying hdfs:/Projects/Tianyu_Test/Resources/RedshiftJDBC42-no-awssdk-1.2.55.1083.jar
2021-07-30 21:25:24,241 INFO Client: Uploading resource file:/tmp/spark-73343462-ce95-4941-8624-c8bf5942ff66/__spark_conf__9159800395989873445.zip → hdfs:/Projects/Tianyu_Test/Resources/.sparkStaging/application_1627330751135_0006/spark_conf.zip
2021-07-30 21:25:24,819 INFO SecurityManager: Changing view acls to: livy,Tianyu_Test__tqiu0000
2021-07-30 21:25:24,819 INFO SecurityManager: Changing modify acls to: livy,Tianyu_Test__tqiu0000
2021-07-30 21:25:24,820 INFO SecurityManager: Changing view acls groups to:
2021-07-30 21:25:24,821 INFO SecurityManager: Changing modify acls groups to:
2021-07-30 21:25:24,821 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(livy, Tianyu_Test__tqiu0000); groups with view permissions: Set(); users with modify permissions: Set(livy, Tianyu_Test__tqiu0000); groups with modify permissions: Set()
2021-07-30 21:25:24,888 INFO EsServiceCredentialProvider: Loaded EsServiceCredentialProvider
2021-07-30 21:25:26,245 INFO EsServiceCredentialProvider: Hadoop Security Enabled = [false]
2021-07-30 21:25:26,245 INFO EsServiceCredentialProvider: ES Auth Method = [SIMPLE]
2021-07-30 21:25:26,245 INFO EsServiceCredentialProvider: Are creds required = [false]
2021-07-30 21:25:26,255 INFO Client: Submitting application application_1627330751135_0006 to ResourceManager
2021-07-30 21:25:26,334 INFO YarnClientImpl: Submitted application application_1627330751135_0006
2021-07-30 21:25:26,350 INFO Client: Application report for application_1627330751135_0006 (state: GENERATING_SECURITY_MATERIAL)
2021-07-30 21:25:26,383 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1627680326285
final status: UNDEFINED
tracking URL: https://resourcemanager.service.consul:8089/proxy/application_1627330751135_0006/
user: Tianyu_Test__tqiu0000
2021-07-30 21:25:26,416 INFO ShutdownHookManager: Shutdown hook called
2021-07-30 21:25:26,418 INFO ShutdownHookManager: Deleting directory /tmp/spark-1dacb782-d007-49a4-b54a-16f0193ab006
2021-07-30 21:25:26,931 INFO ShutdownHookManager: Deleting directory /tmp/spark-73343462-ce95-4941-8624-c8bf5942ff66
stderr:
YARN Diagnostics:
Application application_1627330751135_0006 was killed by user livy at 10.198.0.4.
Some things to try:
a) Make sure Spark has enough available resources for Jupyter to create a Spark context.
b) Contact your Jupyter administrator to make sure the Spark magics library is configured correctly.
c) Restart the kernel.