Hello!
We have a DWH Oracle, we want to connect it to the feature store, for On-Demand data retrieval
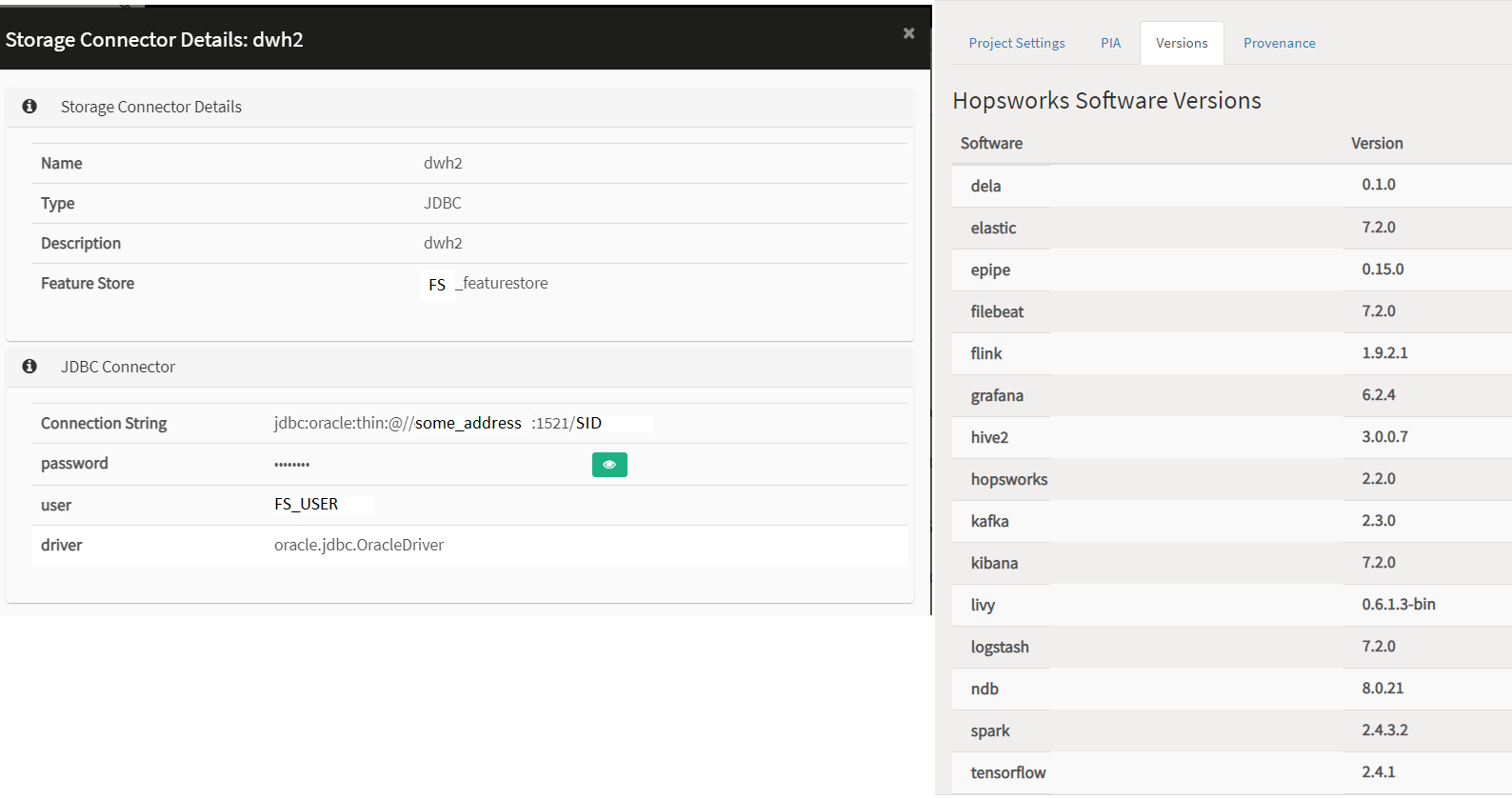
There is a correctly configured connector
Oracle Database Version 19c
Ojdbc driver - ojdbc8-19.9.0.0.jar ( I tried several versions of ojdbc driver, the result is the same )
Сurrent versions of services
I am trying to execute the following code to create a feature
import hsfs
# Create a connection
connection = hsfs.connection()
# Get the feature store handle for the project’s feature store
fs = connection.get_feature_store()
dwh = fs.get_storage_connector(‘dwh2’)
p_query="""(select 1 as ID FROM DUAL)"""
fea = fs.create_on_demand_feature_group(
name=‘fea’,
version=None,
query=p_query,
description=‘On-Demand data from Oracle’,
storage_connector = dwh,
statistics_config = True
)
fea .save()
After which I get the following error
An error was encountered:
An error occurred while calling o189.load.
: java.sql.SQLSyntaxErrorException: ORA-00911: invalid character
at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:509)
at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:461)
at oracle.jdbc.driver.T4C8Oall.processError(T4C8Oall.java:1104)
at oracle.jdbc.driver.T4CTTIfun.receive(T4CTTIfun.java:553)
at oracle.jdbc.driver.T4CTTIfun.doRPC(T4CTTIfun.java:269)
at oracle.jdbc.driver.T4C8Oall.doOALL(T4C8Oall.java:655)
at oracle.jdbc.driver.T4CPreparedStatement.doOall8(T4CPreparedStatement.java:270)
at oracle.jdbc.driver.T4CPreparedStatement.doOall8(T4CPreparedStatement.java:91)
at oracle.jdbc.driver.T4CPreparedStatement.executeForDescribe(T4CPreparedStatement.java:807)
at oracle.jdbc.driver.OracleStatement.executeMaybeDescribe(OracleStatement.java:983)
at oracle.jdbc.driver.OracleStatement.doExecuteWithTimeout(OracleStatement.java:1168)
at oracle.jdbc.driver.OraclePreparedStatement.executeInternal(OraclePreparedStatement.java:3666)
at oracle.jdbc.driver.T4CPreparedStatement.executeInternal(T4CPreparedStatement.java:1426)
at oracle.jdbc.driver.OraclePreparedStatement.executeQuery(OraclePreparedStatement.java:3713)
at oracle.jdbc.driver.OraclePreparedStatementWrapper.executeQuery(OraclePreparedStatementWrapper.java:1167)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD$.resolveTable(JDBCRDD.scala:61)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRelation$.getSchema(JDBCRelation.scala:210)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:35)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:167)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: Error : 911, Position : 43, Sql = SELECT * FROM ((select 1 as ID FROM DUAL)) __SPARK_GEN_JDBC_SUBQUERY_NAME_1 WHERE 1=0, OriginalSql = SELECT * FROM ((select 1 as ID FROM DUAL)) __SPARK_GEN_JDBC_SUBQUERY_NAME_1 WHERE 1=0, Error Msg = ORA-00911: invalid character
at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:513)
… 32 more
Traceback (most recent call last):
File “/srv/hops/anaconda/envs/theenv/lib/python3.7/site-packages/hsfs/feature_group.py”, line 1278, in save
self._feature_group_engine.save(self)
File “/srv/hops/anaconda/envs/theenv/lib/python3.7/site-packages/hsfs/core/on_demand_feature_group_engine.py”, line 26, in save
feature_group, “read_ondmd”
File “/srv/hops/anaconda/envs/theenv/lib/python3.7/site-packages/hsfs/engine/spark.py”, line 110, in register_on_demand_temporary_table
on_demand_fg.query, on_demand_fg.storage_connector
File “/srv/hops/anaconda/envs/theenv/lib/python3.7/site-packages/hsfs/engine/spark.py”, line 83, in _jdbc
self._spark_session.read.format(self.JDBC_FORMAT).options(**options).load()
File “/srv/hops/spark/python/lib/pyspark.zip/pyspark/sql/readwriter.py”, line 172, in load
return self._df(self._jreader.load())
File “/srv/hops/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py”, line 1257, in call
answer, self.gateway_client, self.target_id, self.name)
File “/srv/hops/spark/python/lib/pyspark.zip/pyspark/sql/utils.py”, line 63, in deco
return f(*a, **kw)
File “/srv/hops/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py”, line 328, in get_return_value
format(target_id, “.”, name), value)
py4j.protocol.Py4JJavaError: An error occurred while calling o189.load.
: java.sql.SQLSyntaxErrorException: ORA-00911: invalid character
at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:509)
at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:461)
at oracle.jdbc.driver.T4C8Oall.processError(T4C8Oall.java:1104)
at oracle.jdbc.driver.T4CTTIfun.receive(T4CTTIfun.java:553)
at oracle.jdbc.driver.T4CTTIfun.doRPC(T4CTTIfun.java:269)
at oracle.jdbc.driver.T4C8Oall.doOALL(T4C8Oall.java:655)
at oracle.jdbc.driver.T4CPreparedStatement.doOall8(T4CPreparedStatement.java:270)
at oracle.jdbc.driver.T4CPreparedStatement.doOall8(T4CPreparedStatement.java:91)
at oracle.jdbc.driver.T4CPreparedStatement.executeForDescribe(T4CPreparedStatement.java:807)
at oracle.jdbc.driver.OracleStatement.executeMaybeDescribe(OracleStatement.java:983)
at oracle.jdbc.driver.OracleStatement.doExecuteWithTimeout(OracleStatement.java:1168)
at oracle.jdbc.driver.OraclePreparedStatement.executeInternal(OraclePreparedStatement.java:3666)
at oracle.jdbc.driver.T4CPreparedStatement.executeInternal(T4CPreparedStatement.java:1426)
at oracle.jdbc.driver.OraclePreparedStatement.executeQuery(OraclePreparedStatement.java:3713)
at oracle.jdbc.driver.OraclePreparedStatementWrapper.executeQuery(OraclePreparedStatementWrapper.java:1167)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD$.resolveTable(JDBCRDD.scala:61)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRelation$.getSchema(JDBCRelation.scala:210)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:35)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:318)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:223)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:167)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: Error : 911, Position : 43, Sql = SELECT * FROM ((select 1 as ID FROM DUAL)) __SPARK_GEN_JDBC_SUBQUERY_NAME_1 WHERE 1=0, OriginalSql = SELECT * FROM ((select 1 as ID FROM DUAL)) __SPARK_GEN_JDBC_SUBQUERY_NAME_1 WHERE 1=0, Error Msg = ORA-00911: invalid character
at oracle.jdbc.driver.T4CTTIoer11.processError(T4CTTIoer11.java:513)
… 32 more
Help, please, where to look for a solution to the problem?