Hello,
we need to access files from Azure blob storage and it looks we may need to add jars to spark, so I included them through the Jupiter add jars option but seems not to work that way. So into /srv/hops/spar/jars folder from the cluster is where I need to add the additional jars?
Regards
Hi,
I included them through the Jupiter add jars option but seems not to work that way
Did you get an error like class was not found?
So into /srv/hops/spar/jars folder from the cluster is where I need to add the additional jars?
Yes that is the default location where Spark loads jars from
Hi @Theo i had this error and after google it every note i foud pointed to a missing libraries, so i add them thru Jupyter and the error persist, not really sure is a pyspark library missing or spark
Py4JJavaError: An error occurred while calling o36.parquet.
: java.io.IOException: No FileSystem for scheme: wasbs
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2660)
Does the error occur for both Spark and PySpark kernels?
Does it work if you put the jars in spark jars folder?
If you are trying it with PySpark you may need to install the azure-storage-blob first https://docs.microsoft.com/en-us/azure/storage/blobs/storage-quickstart-blobs-python#install-the-package
From the error message it seems that you are not providing the class implementing the FileSystem interface for wasbs.
Are you adding the hadoop-azure jar as well? (https://hadoop.apache.org/docs/current/hadoop-azure/index.html) If so, which version are you using? If not, can you try to add version 2.8.5 (you can download it from maven central: https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-azure/2.8.5)
–
Fabio
I noticed the jars are been included (selecting the jupyter app from the admin site an then selting -> environment) they are there. so i did more research and turns out i needed to add hadoops configuration like this:
Blockquote “”“How to set hadoop configuration values from pyspark”""
sc._jsc.hadoopConfiguration().set(“fs.azure.sas.”+container_name+"."+storage_account_name+".blob.core.windows.net",sas_access_key)
sc._jsc.hadoopConfiguration().set(“fs.azure”,“org.apache.hadoop.fs.azure.NativeAzureFileSystem”)
sc._jsc.hadoopConfiguration().set(“spark.hadoop.fs.wasbs.impl”,“org.apache.hadoop.fs.azure.NativeAzureFileSystem”)
sc._jsc.hadoopConfiguration().set(“fs.wasbs.impl”,“org.apache.hadoop.fs.azure.NativeAzureFileSystem”)
sc._jsc.hadoopConfiguration().set(“fs.AbstractFileSystem.wasbs.impl”, “org.apache.hadoop.fs.azure.Wasbs”)
sc._jsc.hadoopConfiguration().set(“spark.hadoop.fs.adl.impl”, “org.apache.hadoop.fs.adl.AdlFileSystem”)
and so far i’ stock here ::
An error occurred while calling o789.partitions.
: java.lang.NoClassDefFoundError: org/apache/hadoop/fs/StreamCapabilities
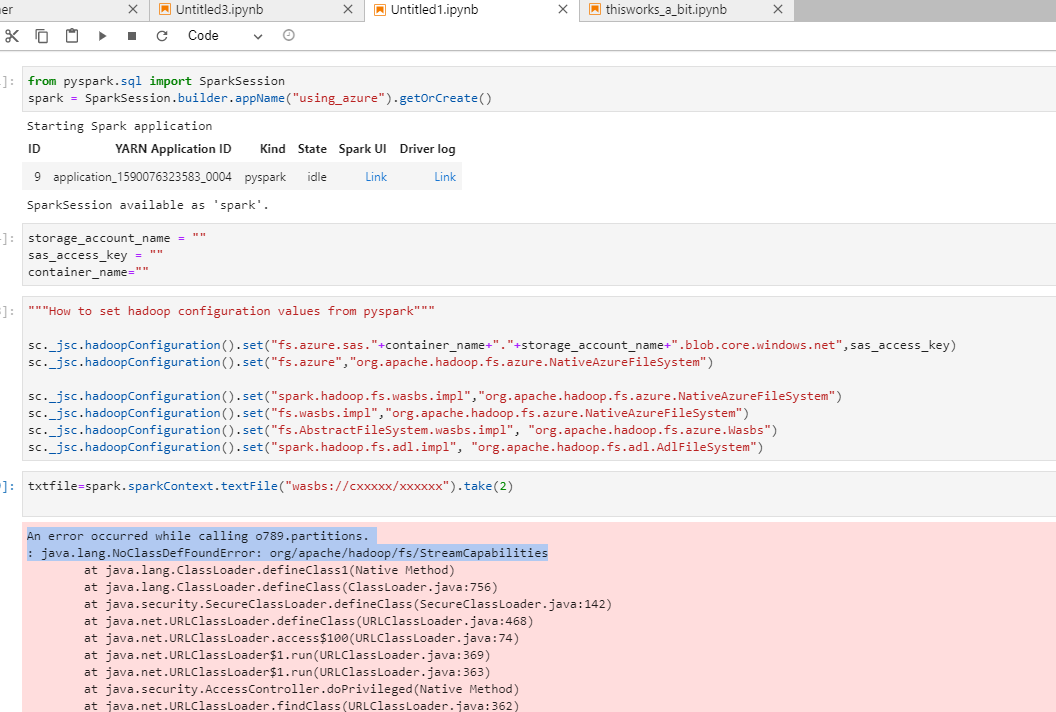
StreamCapabilities.java is an interface introduced in Hadoop 3 - We are not using that version yet.
Could you please post the set of libraries you include in your job?
It might be that downgrading the verison of one of the libraries solves your issue.
–
Fabio
thank you for your response, here they are:
- hadoop-azure-3.2.1.jar
- azure-storage-8.6.4.jar
I’d try to downgrade the hadoop-azure dependency to something like 2.8.5
thanks a lot ! i use hadoop-azure-2.8.5.jar and works fine.